

Some of the key concerns our customers have when they hear that cside operates as a proxy is “what happens if cside goes down?” or “will it add latency?”
The fact is, we designed our products for various levels of ‘bad days’. In a global downtime incident, low tech is the right way to go. By stepping out of the way, we make sure our outage doesn’t become your outage. In this blogpost we’ll go into detail about how to build a runtime service for maximum customer up-time.
TLDR:
- We usually make websites faster. This depends on your scripts and how many are cacheable. cside can be implemented without any latency added depending on the hybrid implementation. We run in many different regions, this number changes all the time but at least 9 different geo-locations is the norm. While proxying close to a user directly reduces potential added latency, having multiple locations allows us to run routing from point to point over faster routes instead of standard BGP routes.
- If cside faces an incident, there are multiple failsafes in place. Incidents rarely result in customer impact, let alone actual downtime of the runtime service.
- If the cside goes down**, we stop the script that routes your traffic through us.**By removing the cside from the traffic flow there wouldn’t be any impact to the customer’s site. Imagine this architecture as a virtual dead-man switch.
Which solutions does cside offer?
cside offers 3 approaches to client-side dependency security:
- Direct mode - Easiest & rather safe
Usecase: I care about client-side security and I need something that will be easy to explain to the rest of the team and I am willing to make some trade-offs to not cause organizational confusion.
Operating model: allow the script to serve directly for 3rd party sources I trust, scripts I don’t trust get the full security treatment. First party scripts get checked client-side and fetched by cside.
Pros: Easiest to implement - just add a script. (almost) No performance impact - wrapping JS in the browser can add a negligible amount of added latency (single digit milliseconds). Ability to stop script actions or block by script URL, hash or domain.
Cons: Not always guaranteed to check the same script payload as the user got - but it's close. No performance gains on static or optimizable scripts. Actions in the browser are basically exposed, even when heavily obfuscated.
Implementation: Add our script to your website.
You can still put cside between untrusted scripts and the end user.
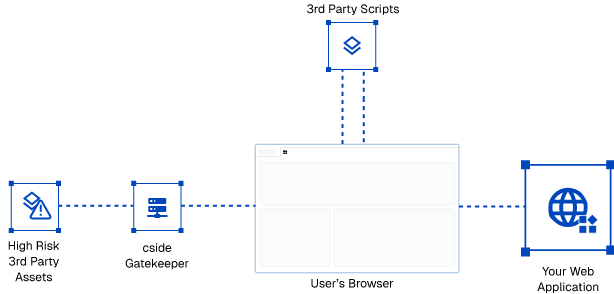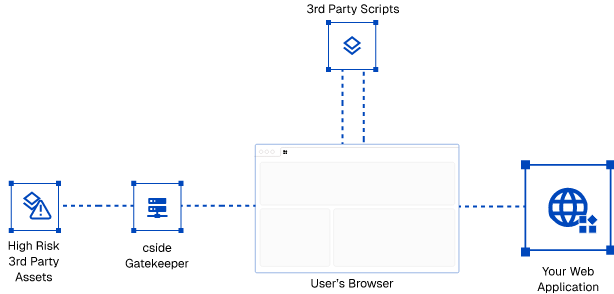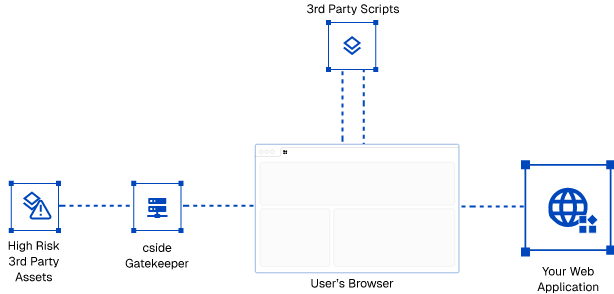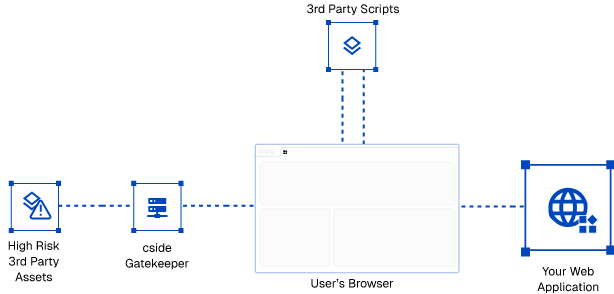
- Gatekeeper mode - Safest
Usecase: I’m a high value target and need full security control.
Operating model: all 3rd party scripts pass through cside except some I selected, first party scripts get checked client-side and fetched by cside.
Pros: Full visibility. Full control. Performance increase on some scripts. We know that what the user got is what we checked. We don't have to deal with limitations in browsers, we have control over the script delivery and have full forensics visibility.
Cons: The word "proxy" comes to mind and causes people to be concerned, but we'll explain below why in this case it shouldn't matter. On highly dynamic scripts latency can be added. Static scripts are usually delivered faster.
Implementation: Add our script to your site Flag scripts you trust and don’t need cside to serve. By default, we don’t gate-keep some scripts that are incompatible with being served by a different URL. Operating model: all scripts pass through cside except some.
- Scan Mode - Fastest
Use-case: I don’t have the ability to add a script to the website.
Operating model: I need to keep an eye, I can't really add anything to the site so observability is a good start.
Pros: Cheap Fast and easy to setup cside threat intel gathered by thousands of other websites with combined billions of visitors.
Cons: Client-side attacks are dynamic, a static scan is by design less likely to spot an attack. A highly targeted attack could succeed at avoiding detection.
Why we approach it this way
The cside team has been in client-side security for a while across various vendors.
We understand the limitations and actively contribute to standards bodies like the W3C to help make client-side security technically viable.
Client-side detections are easy to reverse engineer and circumvent by specification. Browsers, unlike most operating systems don't allow security vendors to have more control or priority. What a script for client-side security essentially does is wrap APIs that can be used by bad actors and monitor which scripts use them. Unfortunately, too strict client-side detections could break some client-side libraries. The problem is that not every script plays nicely with wrapped APIs.
By combining the detections in the browser with detections on our own engine we create a balanced best of all worlds scenario. Balancing detection ability with ease of use with resilience and ultimately giving the customer the ability to choose the approach.
Why cside is different than traditional 'proxy' services
When most people think of a proxy, they immediately think of Cloudflare, Akamai, Fastly, etc While those are excellent for general-purpose CDN and DDoS protection, cside.com represents a fundamentally different approach.
Instead of proxying HTTP traffic like traditional proxies and firewalls, we gatekeep the browser-based components and JavaScripts that the end user would load into their browser from the public internet while visiting your website or web application. Thus allowing complete script visibility, seeing what the end user sees and blocking any malicious attempts to skim or harvest PII, credit card details, cryptowallet IDs.Traditional proxies typically operate on an all-or-nothing principle. This creates a single point of failure and limited operational flexibility. cside’s hybrid approach changes the game entirely by allowing selective proxying and having script-by-script control, full proxy or capture-only mode. Moreover we operate with a fail‑open design so we would never affect your website, payment pages or checkouts in case of an incident.
The type of incident matters
There are a range of possible causes for disruption:
- Code changes
- Unexpected substantial load
- Upstream provider outages
For each, we have a runbook.
For each, we have preventive measures.
For each, we have redundancy.
We’re not taking any risk.
Preventing outages that result from code changes
Like most enterprise grade companies, we have a rigorous testing process in place and have pressure tested our code before it makes it to production.
Moreover, we have “development” and “staging” environments where we thoroughly test our changes before they even get to production. Our staging environment is a full mirror of production, gatekeeping engine and all, so every update gets tested in the same setup our users rely on. That way we make sure that the proxy is fully functional after every change.
Our engine runs in a fully distributed setup across multiple regions, so users will hit the instance closest to them. When we are ready to move to production, we do phased roll-outs across our regions. The new code is deployed to one region first, and progressively expanded to the others. In the unlikely event of a bad code change reaching this point, it’s contained and detected early in that first region before rollout continues globally.
Something is wrong, what now? Redundancy by protocol.
By design, cside is a hybrid proxy. Meaning we can be implemented to proxy on some, all or most scripts except those we explicitly don’t proxy. And that is completely configurable by our customers.
By default we don’t proxy first party scripts and specific scripts that prevent proxying by design. That doesn’t mean we’re ignoring them. We just handle them a little differently. They still flow through our pipeline so they get analysed, we still fetch their content even if the proxy is not serving them and we still can notify our customers if something looks off.
And for cases where a script is really sensitive and customers don’t want it going through the proxy at all, it can be completely excluded.
This flexibility is very valuable to us as it allows us options to quickly adjust our behaviours on the customer site. When an incident occurs or we must quickly debug, we have options to limit impact right away.
For example: if the proxy ever had downtime, we could immediately stop serving the scripts by one of the mechanisms mentioned above, to avoid pages from breaking. Some of these controls are also available in the dashboard for customers to configure it themselves.
Usually, when something starts to go wrong, one or our internal non-public services would show indicators of an issue before it becomes critical. At this point our incident alerting would come into effect. The cside team runs a 24/7 global on-call rotation, with escalations to subject matter experts. We’re planning on releasing a blogpost on our incident management processes soon, stay tuned!
On top of that, we have built backup secondary services ready in our back-end for any services to stay highly available, and to cover even in disaster scenarios. For example, in the case of the proxy, if the primary proxy would not be able to handle the load because of an unexpected traffic spike, a secondary service is ready to take over.
In the near future, cside plans to use anycast IPs to load balance automatically to an alternative location by protocol. This is more than a redundancy factor, it is also a performance increasing design decision.
cside is down, what happens next?
Good news, this hasn’t happened. If it ever does, it would mean a whole chain of failsafes failed. Still, we are ready.
Here’s how it works. In case our proxy goes down, our client-side script would not route traffic to cside. In other words, your site just carries on without us. Sounds low tech right? This is by design. In a global downtime incident, low tech is the right way to go. By stepping out of the way, we make sure our outage doesn’t become your outage.
The only traffic at that point we have to worry about is server-side prefixed scripts. Those are covered too. We handle these with a fall-back proxy that redirects the scripts to their original source. This is a lot less computationally heavy and this infrastructure runs on an infinitely scalable third party service.
The result: no impact to a customer’s uptime. The only tradeoff, during this incident we’d not have visibility through our proxy service.
That said, a sudden global downtime event is quite rare and extremely unlikely.
Usually, we see warning signs way in advance, so we have enough time to react.
Customers will always be reachable!
We started cside because we knew that all other methods that existed in the market gave a false sense of security and did not have the visibility required to protect their customers. Having to build and maintain a fast distributed proxy is not a small task. We knew the risk and we signed up to address them. It is also important to flag that client-side 3rd party scripts today are usually unmonitored, including for uptime SLA’s. We find outdated URLs live on websites hourly. This is very common. We’ll give you visibility and assurance you didn’t have before. Uptime matters and you don’t have uptime visibility on client-side 3rd party dependencies today, but if you used cside, that would change.
By design, we make sure to avoid any single point of failure and use straight forward low tech fail safes. The low-tech failsafe method is often the most reliable in an incident.










