

L'une des principales préoccupations de nos clients lorsqu'ils apprennent que cside fonctionne comme un proxy est : « que se passe-t-il si cside tombe ? » ou « est-ce que ça va ajouter de la latence ? »
En réalité, nous avons conçu nos produits pour faire face à différents niveaux de « mauvais jours ». En cas de panne mondiale, la simplicité technique est la bonne approche. En s'effaçant du chemin, nous faisons en sorte que notre panne ne devienne pas la vôtre. Dans cet article, nous allons détailler comment construire un service d'exécution en temps réel pour maximiser la disponibilité des clients.
TLDR :
- Nous rendons généralement les sites web plus rapides. Cela dépend de vos scripts et du nombre pouvant être mis en cache. cside peut être implémenté sans latence ajoutée selon l'implémentation hybride choisie. Nous opérons dans de nombreuses régions différentes — ce nombre évolue constamment, mais au moins 9 localisations géographiques différentes est la norme. Le fait de proxifier au plus près de l'utilisateur réduit directement la latence potentielle, tandis que la présence de plusieurs localisations nous permet d'effectuer le routage de point à point via des routes plus rapides que les routes BGP standard.
- Si cside rencontre un incident, plusieurs mécanismes de sécurité sont en place. Les incidents entraînent rarement un impact pour les clients, et encore moins une véritable interruption du service d'exécution.
- Si cside tombe, nous arrêtons le script qui route votre trafic via nous. En retirant cside du flux de trafic, il n'y aurait aucun impact sur le site du client. Imaginez cette architecture comme un interrupteur de sécurité virtuel.
Quelles solutions cside propose-t-il ?
cside propose 3 approches pour la sécurité des dépendances côté client :
- Mode Direct — Le plus simple et plutôt sûr
Cas d'usage : je me soucie de la sécurité côté client, j'ai besoin de quelque chose de facile à expliquer au reste de l'équipe et je suis prêt à faire quelques compromis pour ne pas créer de confusion organisationnelle.
Modèle de fonctionnement : les scripts provenant de sources tierces de confiance sont servis directement ; les scripts non fiables bénéficient du traitement de sécurité complet. Les scripts first-party sont vérifiés côté client et récupérés par cside.
Avantages : Le plus facile à implémenter — il suffit d'ajouter un script. (Presque) aucun impact sur les performances — l'encapsulation du JS dans le navigateur peut ajouter une latence négligeable (quelques millisecondes à un chiffre). Possibilité de bloquer des actions de scripts ou de les bloquer par URL, hash ou domaine.
Inconvénients : Pas toujours garanti de vérifier le même payload de script que celui reçu par l'utilisateur — mais c'est proche. Aucun gain de performance sur les scripts statiques ou optimisables. Les actions dans le navigateur sont fondamentalement exposées, même lorsqu'elles sont fortement obfusquées.
Implémentation : Ajoutez notre script à votre site web.
Vous pouvez toujours placer cside entre les scripts non fiables et l'utilisateur final.
- Mode Gatekeeper — Le plus sûr
Cas d'usage : je suis une cible de grande valeur et j'ai besoin d'un contrôle de sécurité total.
Modèle de fonctionnement : tous les scripts tiers passent par cside, à l'exception de ceux que j'ai sélectionnés ; les scripts first-party sont vérifiés côté client et récupérés par cside.
Avantages : Visibilité totale. Contrôle total. Amélioration des performances sur certains scripts. Nous savons que ce que l'utilisateur a reçu est bien ce que nous avons vérifié. Nous n'avons pas à gérer les limitations des navigateurs — nous contrôlons la distribution des scripts et disposons d'une visibilité forensique complète.
Inconvénients : Le mot « proxy » vient à l'esprit et inquiète certaines personnes, mais nous expliquerons ci-dessous pourquoi cela ne devrait pas être un problème dans ce cas. Sur les scripts très dynamiques, une latence peut être ajoutée. Les scripts statiques sont généralement distribués plus rapidement.
Implémentation : Ajoutez notre script à votre site. Indiquez les scripts auxquels vous faites confiance et que cside n'a pas besoin de servir. Par défaut, nous ne filtrons pas certains scripts incompatibles avec le fait d'être servis depuis une URL différente. Modèle de fonctionnement : tous les scripts passent par cside, à l'exception de certains.
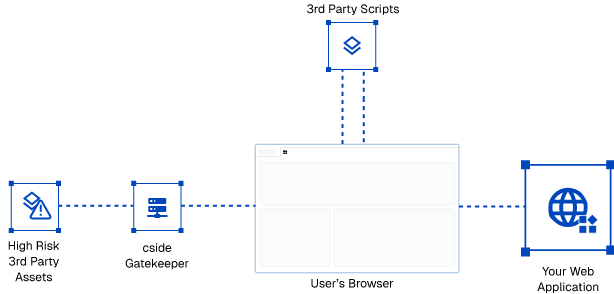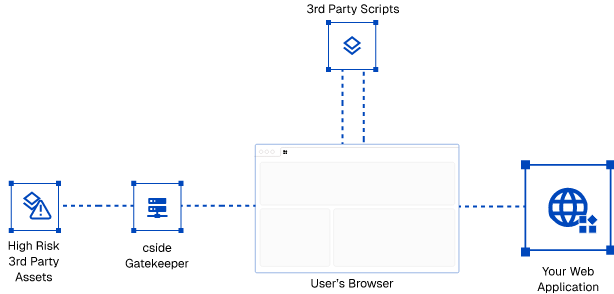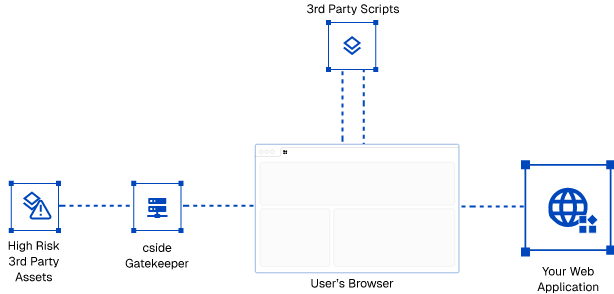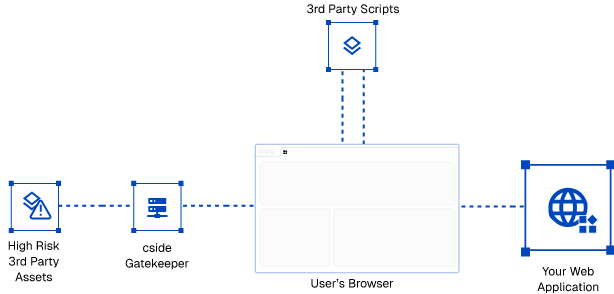
- Mode Scan — Le plus rapide
Cas d'usage : je n'ai pas la possibilité d'ajouter un script au site web.
Modèle de fonctionnement : j'ai besoin de surveiller, je ne peux pas vraiment ajouter quoi que ce soit au site, donc l'observabilité est un bon point de départ.
Avantages : Peu coûteux. Rapide et facile à mettre en place. Renseignements sur les menaces de cside collectés par des milliers d'autres sites web représentant des milliards de visiteurs combinés.
Inconvénients : Les attaques côté client sont dynamiques ; un scan statique est par nature moins susceptible de détecter une attaque. Une attaque très ciblée pourrait réussir à éviter la détection.
Pourquoi nous adoptons cette approche
L'équipe cside travaille dans la sécurité côté client depuis un certain temps, au sein de différents éditeurs.
Nous comprenons les limitations et contribuons activement aux organismes de normalisation comme le W3C pour aider à rendre la sécurité côté client techniquement viable.
Les détections côté client sont faciles à rétro-ingénierer et à contourner par spécification. Les navigateurs, contrairement à la plupart des systèmes d'exploitation, ne permettent pas aux éditeurs de sécurité d'avoir plus de contrôle ou de priorité. Ce que fait essentiellement un script de sécurité côté client, c'est encapsuler les API pouvant être utilisées par des acteurs malveillants et surveiller quels scripts les utilisent. Malheureusement, des détections côté client trop strictes pourraient casser certaines bibliothèques côté client. Le problème est que tous les scripts ne fonctionnent pas bien avec des API encapsulées.
En combinant les détections dans le navigateur avec les détections sur notre propre moteur, nous créons un scénario équilibré qui tire le meilleur de tous les mondes. Nous équilibrons la capacité de détection avec la facilité d'utilisation et la résilience, tout en donnant au client la possibilité de choisir son approche.
Pourquoi cside est différent des services « proxy » traditionnels
Quand la plupart des gens pensent à un proxy, ils pensent immédiatement à Cloudflare, Akamai, Fastly, etc. Bien que ces solutions soient excellentes pour le CDN généraliste et la protection DDoS, cside.com représente une approche fondamentalement différente.
Au lieu de proxifier le trafic HTTP comme les proxies et pare-feux traditionnels, nous filtrons les composants basés sur le navigateur et les JavaScripts que l'utilisateur final chargerait dans son navigateur depuis l'internet public en visitant votre site web ou application web. Cela permet une visibilité complète sur les scripts, de voir ce que voit l'utilisateur final et de bloquer toute tentative malveillante de collecter ou d'exfiltrer des données personnelles, des coordonnées bancaires ou des identifiants de cryptomonnaie. Les proxies traditionnels fonctionnent généralement selon un principe du tout ou rien. Cela crée un point de défaillance unique et une flexibilité opérationnelle limitée. L'approche hybride de cside change complètement la donne en permettant un proxying sélectif et un contrôle script par script, en mode proxy complet ou en mode capture uniquement. De plus, nous fonctionnons avec une conception fail-open afin de ne jamais affecter votre site web, vos pages de paiement ou vos tunnels de commande en cas d'incident.
Le type d'incident est déterminant
Il existe plusieurs causes possibles de perturbation :
- Modifications du code
- Charge importante et inattendue
- Pannes des fournisseurs en amont
Pour chacune, nous disposons d'un runbook.
Pour chacune, nous avons des mesures préventives.
Pour chacune, nous avons de la redondance.
Nous ne prenons aucun risque.
Prévenir les pannes liées aux modifications du code
Comme la plupart des entreprises de niveau enterprise, nous disposons d'un processus de test rigoureux et soumettons notre code à des tests de charge avant qu'il n'atteigne la production.
De plus, nous disposons d'environnements de « développement » et de « staging » où nous testons minutieusement nos modifications avant même qu'elles n'atteignent la production. Notre environnement de staging est un miroir complet de la production, moteur de filtrage inclus, de sorte que chaque mise à jour est testée dans la même configuration que celle sur laquelle nos utilisateurs s'appuient. Nous nous assurons ainsi que le proxy est pleinement fonctionnel après chaque modification.
Notre moteur fonctionne dans une configuration entièrement distribuée sur plusieurs régions, de sorte que les utilisateurs atteignent l'instance la plus proche d'eux. Lorsque nous sommes prêts à passer en production, nous effectuons des déploiements progressifs dans nos régions. Le nouveau code est d'abord déployé dans une région, puis progressivement étendu aux autres. Dans l'éventualité peu probable qu'une mauvaise modification de code atteigne ce stade, elle est contenue et détectée tôt dans cette première région avant que le déploiement ne se poursuive à l'échelle mondiale.
Quelque chose ne va pas, que faire ? La redondance par protocole.
Par conception, cside est un proxy hybride. Cela signifie que nous pouvons être implémentés pour proxifier certains, tous ou la plupart des scripts, à l'exception de ceux que nous ne proxifions pas explicitement. Et cela est entièrement configurable par nos clients.
Par défaut, nous ne proxifions pas les scripts first-party ni les scripts spécifiques qui empêchent le proxying par conception. Cela ne signifie pas que nous les ignorons. Nous les traitons simplement un peu différemment. Ils passent toujours par notre pipeline pour être analysés, nous récupérons toujours leur contenu même si le proxy ne les sert pas, et nous pouvons toujours notifier nos clients si quelque chose semble anormal.
Et pour les cas où un script est vraiment sensible et où les clients ne veulent pas qu'il passe par le proxy du tout, il peut être complètement exclu.
Cette flexibilité nous est très précieuse car elle nous offre des options pour ajuster rapidement nos comportements sur le site du client. Lorsqu'un incident survient ou que nous devons déboguer rapidement, nous avons des options pour limiter immédiatement l'impact.
Par exemple : si le proxy avait une interruption, nous pourrions immédiatement arrêter de servir les scripts via l'un des mécanismes mentionnés ci-dessus, pour éviter que les pages ne se cassent. Certains de ces contrôles sont également disponibles dans le tableau de bord pour que les clients puissent les configurer eux-mêmes.
En général, lorsque quelque chose commence à mal tourner, l'un de nos services internes non publics affiche des indicateurs d'un problème avant qu'il ne devienne critique. À ce stade, nos alertes d'incident entrent en jeu. L'équipe cside assure une rotation d'astreinte mondiale 24h/24 et 7j/7, avec des escalades vers des experts en la matière. Nous prévoyons de publier prochainement un article de blog sur nos processus de gestion des incidents, restez connectés !
En outre, nous avons construit des services secondaires de secours prêts dans notre back-end pour que tous les services restent hautement disponibles, et pour couvrir même les scénarios de catastrophe. Par exemple, dans le cas du proxy, si le proxy principal n'était pas en mesure de gérer la charge en raison d'un pic de trafic inattendu, un service secondaire est prêt à prendre le relais.
Dans un avenir proche, cside prévoit d'utiliser des IP anycast pour équilibrer automatiquement la charge vers un emplacement alternatif par protocole. Il s'agit de plus qu'un facteur de redondance — c'est également une décision de conception visant à améliorer les performances.
cside est en panne, que se passe-t-il ensuite ?
Bonne nouvelle : cela ne s'est jamais produit. Si cela devait arriver, cela signifierait qu'une toute une chaîne de mécanismes de sécurité a échoué. Nous sommes néanmoins prêts.
Voici comment cela fonctionne. Si notre proxy tombe, notre script côté client ne routerait pas le trafic vers cside. En d'autres termes, votre site continue simplement sans nous. Cela semble peu sophistiqué, n'est-ce pas ? C'est voulu. En cas de panne mondiale, la simplicité technique est la bonne approche. En s'effaçant du chemin, nous faisons en sorte que notre panne ne devienne pas la vôtre.
Le seul trafic dont nous devons nous préoccuper à ce stade concerne les scripts préfixés côté serveur. Ceux-ci sont également couverts. Nous les gérons avec un proxy de secours qui redirige les scripts vers leur source d'origine. C'est beaucoup moins gourmand en ressources de calcul et cette infrastructure fonctionne sur un service tiers à l'échelle infiniment extensible.
Le résultat : aucun impact sur la disponibilité du client. Le seul compromis : pendant cet incident, nous n'aurions pas de visibilité via notre service proxy.
Cela dit, un événement de panne mondiale soudaine est assez rare et extrêmement improbable.
En général, nous observons des signes avant-coureurs bien à l'avance, ce qui nous laisse suffisamment de temps pour réagir.
Les clients seront toujours accessibles !
Nous avons créé cside parce que nous savions que toutes les autres méthodes existant sur le marché donnaient un faux sentiment de sécurité et ne disposaient pas de la visibilité nécessaire pour protéger leurs clients. Construire et maintenir un proxy distribué rapide n'est pas une mince affaire. Nous connaissions les risques et nous nous sommes engagés à les adresser. Il est également important de souligner que les scripts tiers côté client sont aujourd'hui généralement non surveillés, y compris en ce qui concerne les SLA de disponibilité. Nous trouvons des URL obsolètes actives sur des sites web toutes les heures. C'est très courant. Nous vous offrirons une visibilité et une assurance que vous n'aviez pas auparavant. La disponibilité est importante et vous n'avez pas aujourd'hui de visibilité sur la disponibilité de vos dépendances tierces côté client — mais si vous utilisiez cside, cela changerait.
Par conception, nous veillons à éviter tout point de défaillance unique et utilisons des mécanismes de sécurité simples et peu sophistiqués. La méthode de sécurité low-tech est souvent la plus fiable lors d'un incident.










