

TL; DR
- Robots.txt is a voluntary directive, not a security control. AI agents and crawlers do not have to comply with your request.
- Robots.txt also leaves an open door for user agent spoofing, when malicious AI agents falsely claim their identity to be a trusted agent like “GPTBot”.
- AI agents that use headless browsers (sometimes locally hosted) are becoming increasingly popular and evade legacy bot detection tools (like Cloudflare).
- Specialized tools (like cside AI Agent Detection) are needed to accurately see what agents are doing on your website and preventing fraudulent agent activity.
- AI crawlers / scrapers are not the only threat. You should block agents that execute promo abuse, credit card testing, content piracy, and chargeback fraud.
4 Methods to Block AI Agents on Your Website (comparison)
<thead>
<tr>
<th>Method</th>
<th>How It Works</th>
<th>Effective against:</th>
<th>Security/Anti-Fraud Depth:</th>
<th>Cost</th>
<th>Implementation Difficulty</th>
</tr>
</thead>
<tbody>
<tr>
<td><strong>robots.txt</strong></td>
<td>
A text file you create and upload onto your website. It tells crawlers which parts of your website they should not access
</td>
<td>
• AI search crawlers from major platforms (Google, ChatGPT)<br>
• AI scrapers that train LLM models
</td>
<td>
<strong>Weak</strong><br>
• Most AI agents do not respect robots.txt<br>
• User-agent spoofing is easy<br>
• No visibility into behavior<br>
• Ineffective against malicious or locally hosted agents
</td>
<td>Free</td>
<td>Easy. Can be implemented by non-technical teams.</td>
</tr>
<tr>
<td><strong>Server controls</strong></td>
<td>
Set rules at the server level to block agents based on IP or user-agent directives.
</td>
<td>
• AI search crawlers from major platforms (Google, ChatGPT)<br>
• AI scrapers that train LLM models
</td>
<td>
<strong>Weak</strong><br>
• IP-based blocking can be bypassed with residential proxies<br>
• HTTP headers can be spoofed<br>
• Requires manual setup that can easily be misconfigured
</td>
<td>Low to moderate (requires time from personnel)</td>
<td>Medium. Requires developer or DevOps support</td>
</tr>
<tr>
<td><strong>Traditional bot detection (like Cloudflare)</strong></td>
<td>
Vendor tool with dashboards. Assigns bot scores using network layer signals, reputation databases, and limited client-side monitoring.
</td>
<td>
• AI search crawlers<br>
• AI scrapers that train LLM models<br>
• Basic bots and scrapers<br>
• DDoS attacks
</td>
<td>
<strong>Medium</strong><br>
• Struggles with locally hosted browser agents<br>
• Limited interaction-level visibility<br>
• Binary allow/deny logic<br>
• Weak governance capabilities
</td>
<td>Low to moderate (depends on pricing plan)</td>
<td>Easy.</td>
</tr>
<tr>
<td><strong>Specialized AI agent detection (like cside)</strong></td>
<td>
Vendor tool with dashboards. Looks at behavioral execution, deep client-side monitoring, and unique signals to spot AI agents more accurately.
</td>
<td>
• AI search crawlers from major platforms (Google, ChatGPT)<br>
• AI scrapers that train LLM models<br>
• Basic bots and scrapers<br>
• Consumer agents running on browser extensions<br>
• Fraudulent AI agents (locally hosted environments, headless browsers)
</td>
<td>
<strong>Strong</strong><br>
• Purpose built to defend against AI agents<br>
• Combines network, application, and interaction level signals<br>
* More accurate detection against headless browser based agents
</td>
<td>Low to moderate (depends on pricing plan)</td>
<td>Easy. Install a snippet of code on your website.</td>
</tr>
</tbody>
</table>
1. Robots.txt
**How it works:**You create a “robots.txt” file that you upload to your website. This text file contains a list of names of AI agents that are allowed or disallowed. When those agents visit your website and read that they are “disallowed” they will refrain from accessing your site. *
** Only agents that choose to respect your robots.txt will be effectively disallowed. This file can be ignored by malicious or misconfigured agents.*
Simplified Example
# Allow OpenAI's crawler (ChatGPT / GPTBot)
User-agent: GPTBot
Allow: /
## Disallow DeepSeek's crawler
User-agent: DeepSeekBot
Disallow: /
Code block: Example of robots.txt directive that allows GPTBot and blocks DeepSeekBot
Most robots.txt files will contain dozens of user-agent directives.
Pros
- Free
- Lots of tools & templates to get started quickly
- Can be set up within a day
- Can implemented by a non technical person
Limitations
- Agents do not haveto respect your robots.txt file. It’s more like a polite request. Crawlers from major AI providers (Meta, Anthropic, OpenAI) tend to respect these directives but these companies are only the tip of the iceberg of total AI agents.
- Malicious AI agents will ignore your robots.txt file.
- Manual maintenance for hundreds of popular AI agent tools, each with multiple agentic identities (crawler, research, action takers).
- Not all AI agents have a public “identity”. Platforms like Selenium and Playwright allow users to create agents that access your website without a clear identity.
- You get zero visibility into behavior. This mechanism merely serves as a “block or not” list. You don’t see how much traffic is agentic or what agents are doing.
Should you use robots.txt: Yes. It’s a great starting point for small businesses and will protect you from major publicly known crawlers like Meta that will otherwise drain server resources. However, this mechanism will not protect you from AI agent fraud.
2. Server Controls
**How it works:**You configure rules at your web server (.htaccess), CDN, or firewall that actually block AI agents via:
- Blocking specific IP addresses or ranges of known agents
- Rate limiting excessive request patterns
- Inspecting HTTP headers
- Looking at user-agent identities (similar to robots.txt)
Unlike robots.txt, server controls have real enforcement power. These rules will block agents or return an error code so that they cannot access your website.
Pros
- Real enforcement against agent traffic
- Mitigates simple scraping agents
- Stops high volume request abuse
- Works well for stopping publicly identified crawlers (Meta, DeepSeek, Google)
Limitations
- Requires technical setup and maintenance often by a web developer
- Malicious AI agents can evade these controls
- IP based blocking can be bypassed by residential proxies or rotating IPs
- HTTP headers can be easily spoofed
- No visibility into behavior. This mechanism will block agents but not give you insights on what agents are doing.
**Bottom line:**If you have the technical personnel, server controls are a strong way to enforce denials against agent crawler requests. This method still falls short in terms of defending against AI agent fraud or AI-assisted website attacks, as malicious agents can create fake identities and pass verification controls.
3. Traditional Bot Detection Tools (e.g. Cloudflare)
Many legacy bot detection products updated their branding to ‘AI agent detection’, but haven’t evolved their actual product sufficiently and fail to detect locally hosted browser or agentic environments built to avoid detections.
**How it works:**Vendor tools like Cloudflare bot detection assign each visitor a “bot score” based on behavioral analysis, fingerprints, reputation data bases of known threats, and other signals.
These vendor tools operate primarily at the CDN or network layer of your website, with some JavaScript injection onto web pages to collect browser signals (client-side monitoring)
Pros
- Relatively easy to install
- Compared to allow/disallow lists, looks at more advanced signals than identity alone
- Proven protection against attacks like DDoS and basic scraping bots
- More automated than manual server controls
Limitations
- Can be evaded by fraudulent AI agents that mimic human behavior
- Struggle to detect locally hosted browser agents, which are increasingly adopted by consumers and attackers
- Rely on application level signals, with very basic interaction level signals,
- No ability to guide consumer AI agents in the purchase journey.
- Weak visibility into client-side signals
Legacy bot detection tools are not ready for AI agents: These solutions were built for an era where bots lived in cloud infrastructure, were not able to reason, and followed predictable patterns. Modern AI agents run inside real browsers and blend into normal traffic. Blanket blocking will stop obvious abuse, but a modern agent governance strategy requires understanding intent and setting dynamic rules.
Our internal tests at cside were able to bypass traditional bot detection on 80/100 attempts with minimal effort.
4. Specialized AI Agent Detection Tools (e.g. cside)
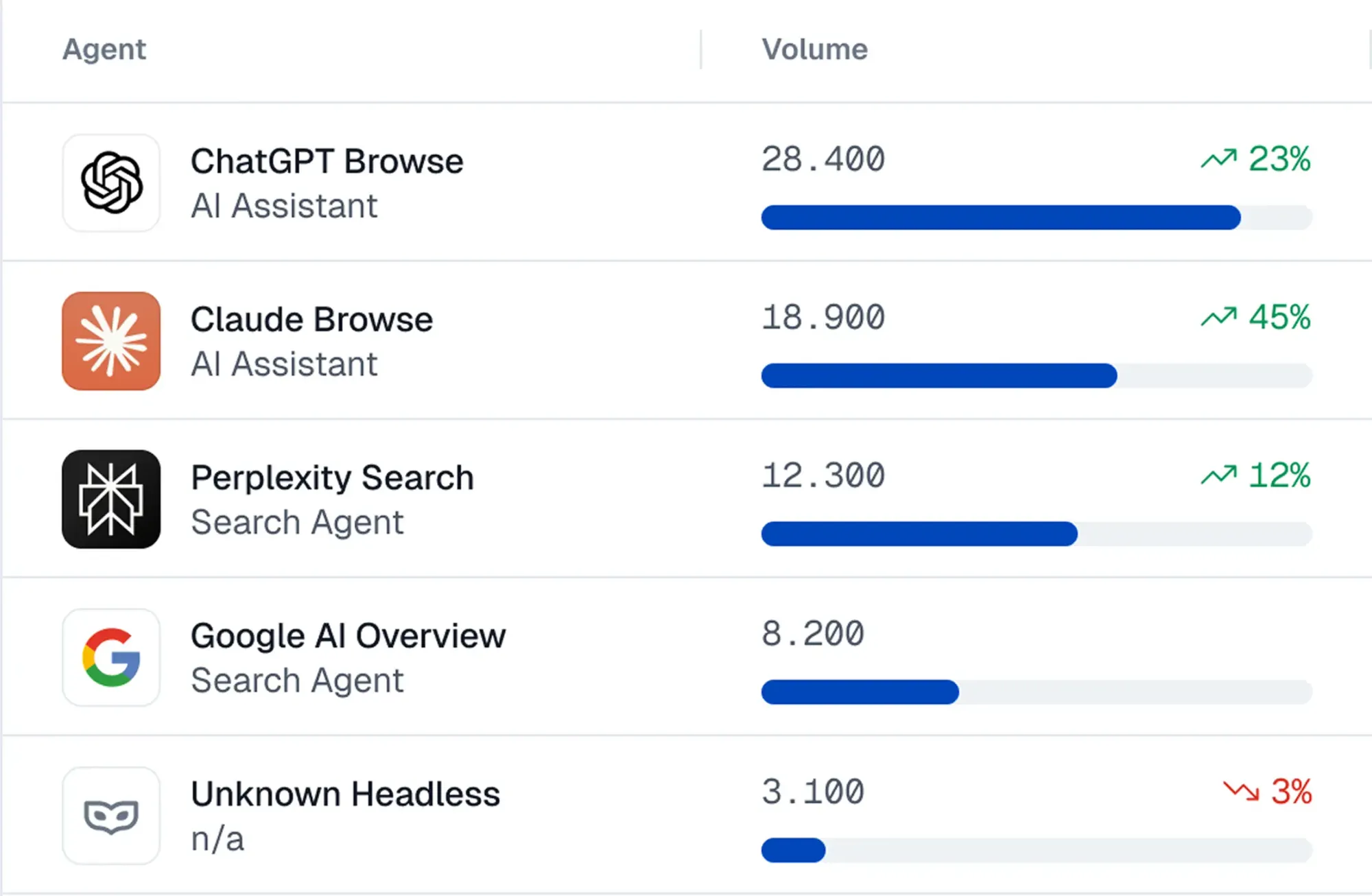
**How it works:**A snippet of code is installed on your site, giving you control over:
- Detection: Observe dozens of signals to identify AI agents, their actions, and fraud risk.
- Blocking: Risk scores are created from a variety of signals - - interaction patterns, fingerprints, JavaScript execution context, reputation databases, honeypots, and more. You can review agent risk and set dynamic rules to block agents outright or allow limited access.
- Governance: A SDK is used by developers to add guardrails to agent sessions. For example, certain steps can ask for human validation, or particular trusted agents can be allowed to make purchases while others are restricted to read only mode.
Pros
- Easy to deploy with dashboards for fraud teams and SDKs for developers
- Purpose built for AI agents. cside is better at detecting locally hosted browser AI agents (e.g. Playwright, Selenium)
- Stronger at detecting agents that operate from browser extensions (Manus AI, Comet)
- Built to prevent agent-based attacks and fraud rather than just “blocking crawlers”
- Governance capabilities to improve agentic commerce experiences
- Visibility into agentic traffic. A dashboard with what agents are on your site, what actions they are taking, where they get stuck, and what risk they bring.
**Modern web security stacks need a specialized AI agent detection tool:**Blocking “bots” and crawlers is no longer enough. AI agents require behavioral classification and dynamic rules. Tools like cside AI Agent detection give enterprises this visibility so that fraud can be blocked without impacting genuine consumer agents.
Why You Should Block (Some) AI Agents From Your Website

Not all AI agents are harmful. Some assist consumers. Some act as research tools. But many agents are fraudulent. A research report from Ahrefs found that 63% of websites receive agentic traffic. That was in early 2025. By now, that percentage is likely higher.
Why block crawlers & scrapers:
The conversation around agentic traffic currently centers on visible crawlers from ChatGPT, Gemini, or other LLM platforms fetching content for answers or to train models. The motivation to block crawlers and scrapers is valid, especially for companies with unique content such as publishers or media streaming services that face:
- Scraping of premium content for piracy
- Harvesting content to train LLM models without permission
Why fraudulent AI agents:
Crawlers from LLM platforms are not the only threat. In fact they are on the “safer” side of the bot automation spectrum. The more concerning threat is how automated abuse from attackers will be amplified by AI agents. Agents make it easier to avoid detection and mimic human behavior.
A report on financial crime from The U.S. Department of the Treasury calls out how AI agents lower the barrier to sophisticated attack techniques that were previously resource constrained, and makes automated fraud accessible to low-skilled attackers.
Agentic threats to security teams:
- Automated account takeover attemptst
- AI-assisted vulnerability discovery
- Abuse of authenticated user flows
- Scripted checkout manipulation
Agentic threats to fraud teams:
- Test stolen credentials at scale
- Abuse promo codes and coupons
- Automate return fraud workflows
- Fake profiles created with document IDs and pictures generated by LLMs
Agentic threats to eCommerce teams:
- Inventory hoarding by automated buyers
- Price scraping
- Affiliate link fraud
How to block AI agents on your website (step by step)
Step 1: Identify the AI Agents on your website (who are they)
With a detection tool:
- To get an instant dashboard of fraudulent AI agents and crawler traffic, you can use cside Agent Detection.
- If your website is connected to Cloudflare you can check their Bot Analytics dashboard for a breakdown of AI crawler traffic.
- For SEO specific visibility on AI crawler traffic you can use Screaming Frog’s log analyzer. This tool will look at your raw server logs and visualize a traffic report.
DIY:
If an AI crawler publicly identifies itself, it will show identifiable signals at the request layer. Check user-agent strings that exist in HTTP requests. To access this information you will have to go to your server logs and search for fields that correlate with AI agent identities:
- GPTBot
- ChatGPT-User
- ClaudeBot
Step 2: Understand what actions AI agents take on your site (what are they doing)
**With a specialized detection tool:**AI agent governance platforms like cside AI Agent Detection or HUMAN Agentic Trust monitor browser execution, navigation flows, and behavioral patterns. This shifts analysis from “is this a bot?” to “what is this bot trying to accomplish?”. A modern detection layer will see:
- Whether an agent is triggering login or checkout workflows
- Repeated attempts against sensitive endpoints
- Automated form submissions
**DIY:**Manually discovering what AI agents are doing requires analyzing server logs, request timing, and JavaScript execution patterns.
Step 3: Understand the intent behind AI agents (are they a risk)
Understanding AI agent intent requires distinguishing between automation that is helpful and automation that is harmful. Traditional bot detection tools were not built to handle agents that mimic human behavior and run from inside an authentic user’s browser environment.
**With a Specialized Detection Tool:**Solutions like cside AI Agent Detection or DataDome’s Agent Trust platform were built for the agentic internet. They help you distinguish between consumer AI agents assisting with research and shopping versus fraudulent AI agents that abuse promo codes, scrape information, or create fake profiles.
Rather than making binary decisions on identity, such platforms use advanced risk scoring rules created by security engineers. These look at signals like:
- Excessive or abnormal requests
- Usage of VPNs or proxies
- Suspicious browser execution environments
- Fingerprinting to catch device re-use in risky workflows (such as promo code redemption)
- Interactions and behavioral analysis
Step 4: Govern AI agents based on behavior (block, trust, or guide)
Once you understand what AI agents are doing on your site, you can decide how to let them interact with your website. The knee-jerk response is to block everything except crawlers that help with SEO or AI search. That approach is good for security, but shuts out legitimate AI agents that might be researching products, booking tickets, filling forms, or submitting inquiries.
This is why traditional bot detection falls short in the agentic era. They give you basic allow/deny logic. The agentic era requires more nuance. Agentic “bots” will be created by consumers on a daily basis, ubiquitous with navigating the internet. A mature agentic governance strategy determines “what should this agentic session be allowed to do”?
For example:
- Research agents may only require read-only access to your website
- Task based agents may be permitted to submit forms or request information.
- Those same task based agents may have their permission for actions revoked on sensitive pages like profile management portals.
Platforms like cside AI Agent Detection support this kind of behavior-based governance. Dashboards make it easy for fraud teams to get data to stop AI agent abuse early. Developers get an SDK and libraries to customize the experience for browser-based agents, enabling agentic commerce further.
Why Robots.txt is not enough to block AI agents
robots.txt is a voluntary directive, not a security control. It requests specified crawlers not to access your site but it does not technically prevent them from doing so. Robots.txt can be a useful mechanism to block major crawlers (Meta, ChatGPT, GoogleBot) who promise to respect this directive, but it doesn’t do much to stop AI agent fraud.
AI assistants & search crawlers do not always comply with robots.txt
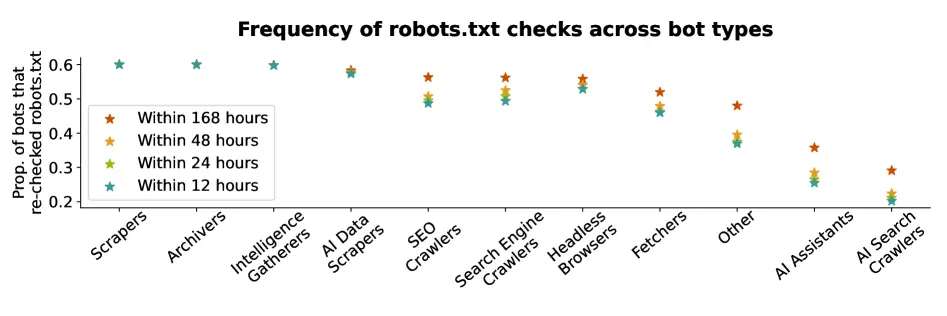
A 2025 academic research report from Duke University shows that only ~60% of AI assistants and AI search crawlers will look at or comply with ‘disallow’ robots.txt requests. That average is likely skewed upwards by bots from ChatGPT and GoogleBot who respect the directive 99%+ of the time.
Some popular bots like Perplexity will only respect the ‘disallow’ directive ~20% of the time.
AI agents using Headless Browsers (like custom-made agents created by consumers) respect robots.txt the least, complying ~10% of the time with ‘disallow’ directives.
User-agent spoofing to evade robots.tx
robots.txt is based on self declared “user-agent strings”. It’s like being asked what your name is. You can self-declare it to be anything you want. If you’re trying to get into an event and you know the name “Brad Pitt” is on the list, you can say that is your name. In the real world you may be asked to show some proof. In contrast, robots.txt has no way of confirming that identities are actually valid.
So fraudulent agents can claim to be “Claudebot” or “GPTBot”. If those identities are allowed on your site, robots.txt will let them right through.
Traditional bot detection (like Cloudflare) misses AI agents
Traditional bot detection systems were designed for an era where automation ran from cloud servers or obvious proxy networks. These systems rely heavily on network-layer signals and reputation databases with limited visibility into JavaScript execution and website interactions.
The rise of locally hosted browser-based automation
A growing class of automation now runs inside real browser environments:
- Consumer agents that run on browser extensions like Manus or Claude’s browser extension
- Automations created by developers that use headless browser tools like Playwright or Selenium that run on machines or even mobile devices
- Fraudulent actors using open source headless browser tools to carry out attacks
This category of agents emerged in part to make it easy for legitimate consumers / developers to ship AI bots that interact with the web. It also emerged as an intentional effort towards avoiding detection from legacy bot governance tools.
These headless browser based agents do not self-identify clearly. In fact they intentionally try to look like a real human user - which makes fraud detection harder (and poisons analytics along the way).
Catching headless browser based agents requires a specialized AI agent detection tool that looks at behavioral signals and deep browser context**.**
How cside helps enterprises block agentic attackers
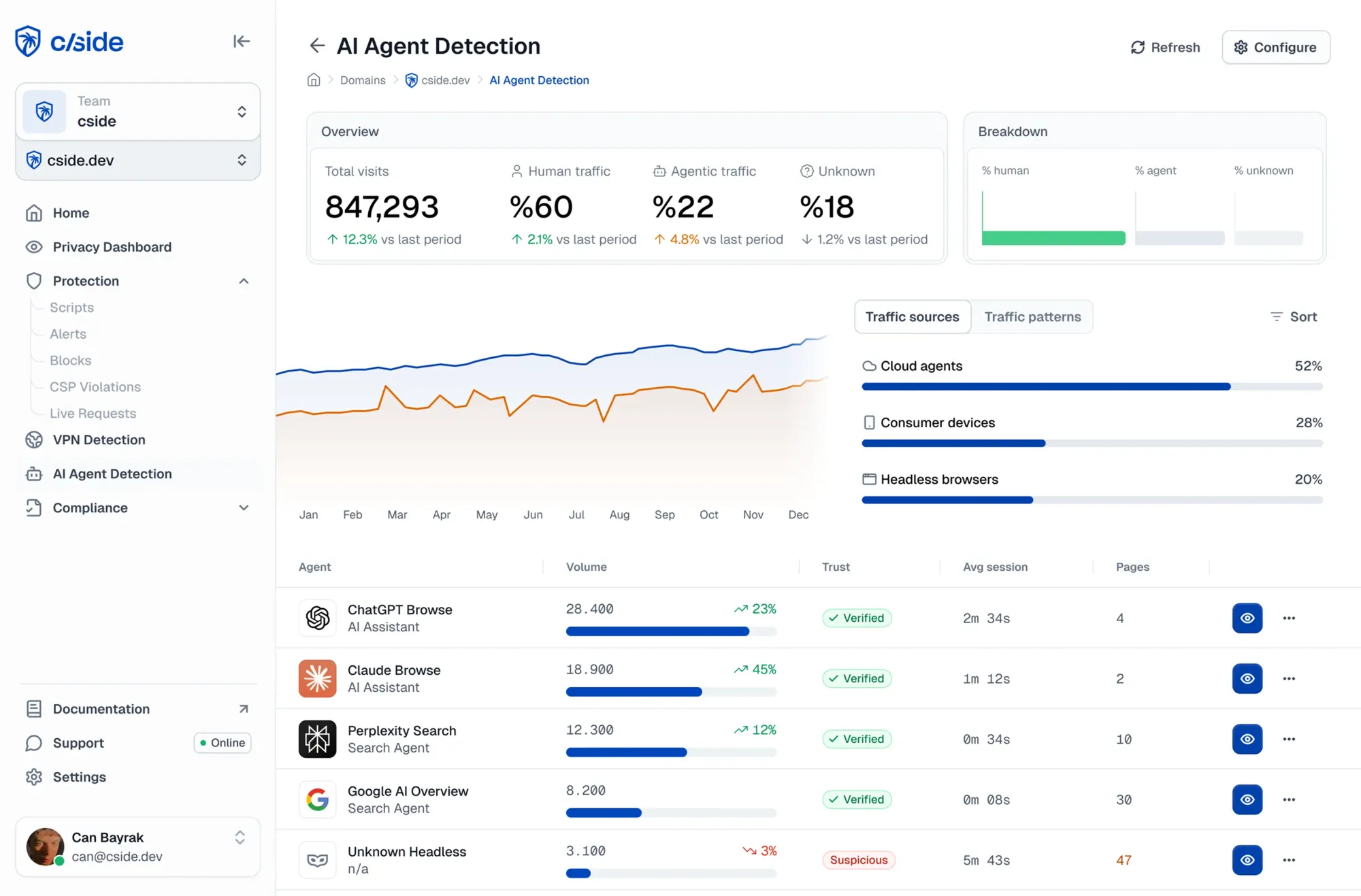
cside is a web security platform, specialized in monitoring browser-layer signals to reduce fraud for enterprises. cside AI Agent Detection helps you identify, classify, and govern agentic traffic on your website.
- Get a dashboard of which agents are accessing your site and what they are doing
- Automatic risk scores from behavioral signals to catch bad AI agents (including browser based and locally hosted ones) that evade traditional bot defenses
- Give your developers tools to put guardrails around what agents can do
- Prevent AI agent fraud such as promo code abuse, content piracy, credit card testing, vulnerability discovery, and advanced scraping.
You can start seeing agentic traffic on your website with a free account.








