

TL ; DR
- robots.txt est une directive volontaire, pas un contrôle de sécurité. Les agents IA et les crawlers ne sont pas tenus de respecter votre demande.
- robots.txt laisse également une porte ouverte à l'usurpation de user-agent, lorsque des agents IA malveillants se font passer pour un agent de confiance comme « GPTBot ».
- Les agents IA qui utilisent des navigateurs headless (parfois hébergés localement) sont de plus en plus répandus et contournent les outils de détection de bots traditionnels (comme Cloudflare).
- Des outils spécialisés (comme cside AI Agent Detection) sont nécessaires pour voir précisément ce que font les agents sur votre site et pour prévenir les activités d'agents frauduleux.
- Les crawlers et scrapers IA ne sont pas les seules menaces. Vous devriez bloquer les agents qui exécutent des abus de promotions, des tests de cartes bancaires, du piratage de contenu et des fraudes aux rétrofacturations.
4 méthodes pour bloquer les agents IA sur votre site web (comparaison)
<thead>
<tr>
<th>Méthode</th>
<th>Comment ça fonctionne</th>
<th>Efficace contre :</th>
<th>Profondeur sécurité / anti-fraude :</th>
<th>Coût</th>
<th>Difficulté de mise en œuvre</th>
</tr>
</thead>
<tbody>
<tr>
<td><strong>robots.txt</strong></td>
<td>
Un fichier texte que vous créez et déposez sur votre site web. Il indique aux crawlers les parties de votre site auxquelles ils ne doivent pas accéder.
</td>
<td>
• Crawlers IA des grandes plateformes (Google, ChatGPT)<br>
• Scrapers IA qui entraînent des modèles LLM
</td>
<td>
<strong>Faible</strong><br>
• La plupart des agents IA ne respectent pas robots.txt<br>
• L'usurpation de user-agent est facile<br>
• Aucune visibilité sur le comportement<br>
• Inefficace contre les agents malveillants ou hébergés localement
</td>
<td>Gratuit</td>
<td>Facile. Peut être mis en place par des équipes non techniques.</td>
</tr>
<tr>
<td><strong>Contrôles serveur</strong></td>
<td>
Définissez des règles au niveau du serveur pour bloquer les agents en fonction de l'IP ou des directives user-agent.
</td>
<td>
• Crawlers IA des grandes plateformes (Google, ChatGPT)<br>
• Scrapers IA qui entraînent des modèles LLM
</td>
<td>
<strong>Faible</strong><br>
• Le blocage par IP peut être contourné avec des proxies résidentiels<br>
• Les en-têtes HTTP peuvent être falsifiés<br>
• Nécessite une configuration manuelle pouvant facilement être mal paramétrée
</td>
<td>Faible à modéré (nécessite du temps de la part du personnel)</td>
<td>Moyen. Nécessite le support d'un développeur ou d'un DevOps</td>
</tr>
<tr>
<td><strong>Détection de bots traditionnelle (comme Cloudflare)</strong></td>
<td>
Outil éditeur avec tableaux de bord. Attribue des scores de bot à partir de signaux de couche réseau, de bases de données de réputation et d'une surveillance client-side limitée.
</td>
<td>
• Crawlers IA de recherche<br>
• Scrapers IA qui entraînent des modèles LLM<br>
• Bots et scrapers basiques<br>
• Attaques DDoS
</td>
<td>
<strong>Moyen</strong><br>
• Difficultés avec les agents navigateur hébergés localement<br>
• Visibilité limitée au niveau des interactions<br>
• Logique binaire autoriser/refuser<br>
• Capacités de gouvernance limitées
</td>
<td>Faible à modéré (selon le plan tarifaire)</td>
<td>Facile.</td>
</tr>
<tr>
<td><strong>Détection spécialisée d'agents IA (comme cside)</strong></td>
<td>
Outil éditeur avec tableaux de bord. Analyse l'exécution comportementale, la surveillance client-side approfondie et des signaux uniques pour identifier les agents IA avec plus de précision.
</td>
<td>
• Crawlers IA des grandes plateformes (Google, ChatGPT)<br>
• Scrapers IA qui entraînent des modèles LLM<br>
• Bots et scrapers basiques<br>
• Agents grand public fonctionnant via des extensions de navigateur<br>
• Agents IA frauduleux (environnements hébergés localement, navigateurs headless)
</td>
<td>
<strong>Solide</strong><br>
• Conçu spécifiquement pour se défendre contre les agents IA<br>
• Combine des signaux réseau, applicatifs et au niveau des interactions<br>
* Détection plus précise des agents basés sur des navigateurs headless
</td>
<td>Faible à modéré (selon le plan tarifaire)</td>
<td>Facile. Installez un extrait de code sur votre site web.</td>
</tr>
</tbody>
</table>
1. Robots.txt
Comment ça fonctionne : Vous créez un fichier « robots.txt » que vous déposez sur votre site web. Ce fichier texte contient une liste de noms d'agents IA autorisés ou interdits. Lorsque ces agents visitent votre site et lisent qu'ils sont « interdits », ils s'abstiennent d'y accéder. *
* Seuls les agents qui choisissent de respecter votre robots.txt seront effectivement bloqués. Ce fichier peut être ignoré par des agents malveillants ou mal configurés.
Exemple simplifié
# Allow OpenAI's crawler (ChatGPT / GPTBot)
User-agent: GPTBot
Allow: /
## Disallow DeepSeek's crawler
User-agent: DeepSeekBot
Disallow: /
Bloc de code : Exemple de directive robots.txt qui autorise GPTBot et bloque DeepSeekBot
La plupart des fichiers robots.txt contiennent des dizaines de directives user-agent.
Avantages
- Gratuit
- De nombreux outils et modèles pour démarrer rapidement
- Peut être mis en place en une journée
- Peut être configuré par une personne non technique
Limites
- Les agents ne sont pas obligés de respecter votre fichier robots.txt. C'est davantage une demande polie. Les crawlers des grands fournisseurs d'IA (Meta, Anthropic, OpenAI) ont tendance à respecter ces directives, mais ces entreprises ne représentent que la partie émergée de l'iceberg de l'ensemble des agents IA.
- Les agents IA malveillants ignoreront votre fichier robots.txt.
- Maintenance manuelle pour des centaines d'outils d'agents IA populaires, chacun disposant de plusieurs identités agentiques (crawler, recherche, exécuteur d'actions).
- Tous les agents IA n'ont pas d'« identité » publique. Des plateformes comme Selenium et Playwright permettent aux utilisateurs de créer des agents qui accèdent à votre site sans identité clairement définie.
- Vous n'avez aucune visibilité sur le comportement. Ce mécanisme sert uniquement de liste « bloquer ou non ». Vous ne voyez pas quelle proportion du trafic est agentique ni ce que font les agents.
Devriez-vous utiliser robots.txt : Oui. C'est un excellent point de départ pour les petites entreprises et cela vous protégera des principaux crawlers publiquement connus comme Meta, qui sinon draineraient les ressources serveur. Cependant, ce mécanisme ne vous protégera pas contre la fraude par agents IA.
2. Contrôles serveur
Comment ça fonctionne : Vous configurez des règles au niveau de votre serveur web (.htaccess), CDN ou pare-feu qui bloquent réellement les agents IA via :
- Le blocage d'adresses IP spécifiques ou de plages d'IP d'agents connus
- La limitation de débit pour les schémas de requêtes excessifs
- L'inspection des en-têtes HTTP
- L'analyse des identités user-agent (similaire à robots.txt)
Contrairement à robots.txt, les contrôles serveur ont un vrai pouvoir d'application. Ces règles bloqueront les agents ou renverront un code d'erreur afin qu'ils ne puissent pas accéder à votre site.
Avantages
- Application réelle contre le trafic agentique
- Atténue les agents de scraping simples
- Stoppe les abus de requêtes à volume élevé
- Fonctionne bien pour bloquer les crawlers publiquement identifiés (Meta, DeepSeek, Google)
Limites
- Nécessite une configuration technique et une maintenance souvent assurées par un développeur web
- Les agents IA malveillants peuvent contourner ces contrôles
- Le blocage par IP peut être contourné par des proxies résidentiels ou des IP rotatives
- Les en-têtes HTTP peuvent être facilement falsifiés
- Aucune visibilité sur le comportement. Ce mécanisme bloquera les agents mais ne vous donnera pas d'informations sur ce qu'ils font.
En résumé : Si vous disposez du personnel technique, les contrôles serveur sont un moyen solide d'appliquer des refus aux requêtes de crawlers agentiques. Cette méthode reste insuffisante pour se défendre contre la fraude par agents IA ou les attaques de sites web assistées par IA, car les agents malveillants peuvent créer de fausses identités et passer les contrôles de vérification.
3. Outils de détection de bots traditionnels (ex. Cloudflare)
De nombreux produits de détection de bots traditionnels ont mis à jour leur image de marque pour parler de « détection d'agents IA », sans faire évoluer suffisamment leur produit réel, et échouent à détecter les navigateurs hébergés localement ou les environnements agentiques conçus pour éviter la détection.
Comment ça fonctionne : Les outils éditeurs comme la détection de bots Cloudflare attribuent à chaque visiteur un « score de bot » basé sur l'analyse comportementale, les empreintes digitales, les bases de données de réputation des menaces connues et d'autres signaux.
Ces outils éditeurs opèrent principalement au niveau CDN ou réseau de votre site web, avec une injection JavaScript sur les pages web pour collecter des signaux navigateur (surveillance client-side).
Avantages
- Relativement facile à installer
- Par rapport aux listes d'autorisation/refus, analyse des signaux plus avancés que la seule identité
- Protection éprouvée contre des attaques comme les DDoS et les bots de scraping basiques
- Plus automatisé que les contrôles serveur manuels
Limites
- Peut être contourné par des agents IA frauduleux qui imitent le comportement humain
- Difficultés à détecter les agents navigateur hébergés localement, de plus en plus adoptés par les consommateurs et les attaquants
- S'appuie sur des signaux au niveau applicatif, avec des signaux au niveau des interactions très basiques
- Aucune capacité à guider les agents IA grand public dans le parcours d'achat
- Visibilité limitée sur les signaux client-side
Les outils de détection de bots traditionnels ne sont pas prêts pour les agents IA : Ces solutions ont été conçues pour une époque où les bots vivaient dans des infrastructures cloud, n'étaient pas capables de raisonner et suivaient des schémas prévisibles. Les agents IA modernes s'exécutent dans de vrais navigateurs et se fondent dans le trafic normal. Le blocage global stoppera les abus évidents, mais une stratégie moderne de gouvernance agentique nécessite de comprendre l'intention et de définir des règles dynamiques.
Nos tests internes chez cside ont réussi à contourner la détection de bots traditionnelle dans 80 tentatives sur 100, avec un effort minimal.
4. Outils spécialisés de détection d'agents IA (ex. cside)
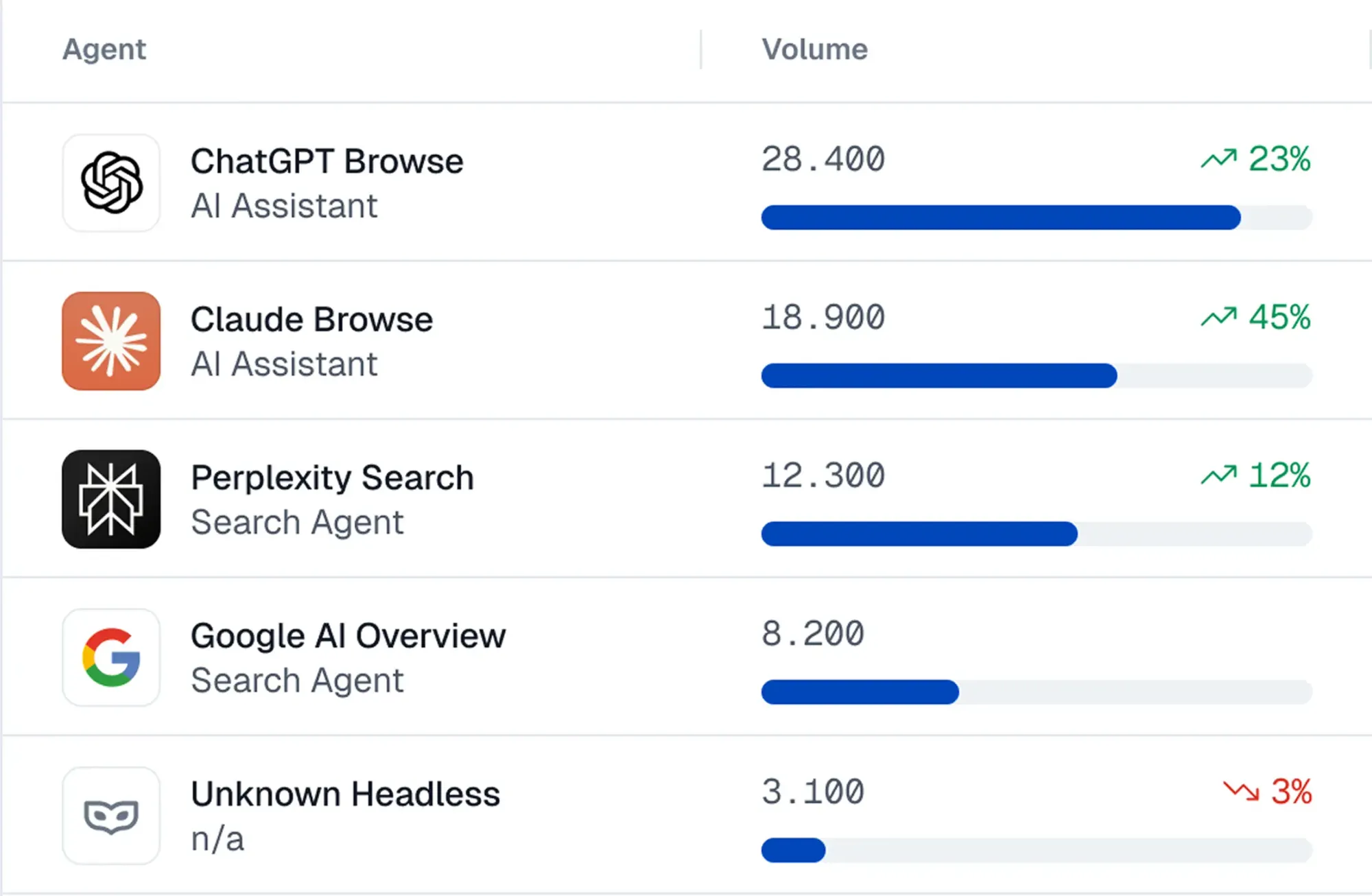
Comment ça fonctionne : Un extrait de code est installé sur votre site, vous donnant le contrôle sur :
- Détection : Observez des dizaines de signaux pour identifier les agents IA, leurs actions et le risque de fraude.
- Blocage : Des scores de risque sont créés à partir d'une variété de signaux — schémas d'interaction, empreintes digitales, contexte d'exécution JavaScript, bases de données de réputation, honeypots, et plus encore. Vous pouvez examiner le risque agentique et définir des règles dynamiques pour bloquer les agents complètement ou leur accorder un accès limité.
- Gouvernance : Un SDK est utilisé par les développeurs pour ajouter des garde-fous aux sessions agentiques. Par exemple, certaines étapes peuvent demander une validation humaine, ou des agents de confiance particuliers peuvent être autorisés à effectuer des achats tandis que d'autres sont limités au mode lecture seule.
Avantages
- Facile à déployer avec des tableaux de bord pour les équipes fraude et des SDK pour les développeurs
- Conçu spécifiquement pour les agents IA. cside est plus performant pour détecter les agents IA navigateur hébergés localement (ex. Playwright, Selenium)
- Plus efficace pour détecter les agents qui opèrent depuis des extensions de navigateur (Manus AI, Comet)
- Conçu pour prévenir les attaques et la fraude par agents plutôt que de simplement « bloquer les crawlers »
- Capacités de gouvernance pour améliorer les expériences de commerce agentique
- Visibilité sur le trafic agentique. Un tableau de bord indiquant quels agents sont sur votre site, quelles actions ils effectuent, où ils bloquent et quel risque ils représentent.
Les stacks de sécurité web modernes ont besoin d'un outil spécialisé de détection d'agents IA : Bloquer les « bots » et les crawlers ne suffit plus. Les agents IA nécessitent une classification comportementale et des règles dynamiques. Des outils comme cside AI Agent detection offrent aux entreprises cette visibilité afin que la fraude puisse être bloquée sans impacter les agents grand public légitimes.
Pourquoi vous devriez bloquer (certains) agents IA de votre site web

Tous les agents IA ne sont pas nuisibles. Certains assistent les consommateurs. D'autres servent d'outils de recherche. Mais beaucoup d'agents sont frauduleux. Un rapport de recherche d'Ahrefs a révélé que 63 % des sites web reçoivent du trafic agentique. C'était début 2025. Depuis, ce pourcentage est probablement plus élevé.
Pourquoi bloquer les crawlers et scrapers :
La discussion autour du trafic agentique se concentre actuellement sur les crawlers visibles de ChatGPT, Gemini ou d'autres plateformes LLM qui récupèrent du contenu pour formuler des réponses ou entraîner des modèles. La motivation pour bloquer les crawlers et scrapers est valide, notamment pour les entreprises disposant de contenu unique comme les éditeurs ou les services de streaming qui font face à :
- Le scraping de contenu premium à des fins de piratage
- La collecte de contenu pour entraîner des modèles LLM sans autorisation
Pourquoi les agents IA frauduleux :
Les crawlers des plateformes LLM ne sont pas la seule menace. En réalité, ils se situent du côté « plus sûr » du spectre de l'automatisation par bots. La menace plus préoccupante réside dans la façon dont les abus automatisés des attaquants seront amplifiés par les agents IA. Les agents facilitent l'évitement de la détection et l'imitation du comportement humain.
Un rapport sur la criminalité financière du Département du Trésor américain souligne comment les agents IA abaissent la barrière à des techniques d'attaque sophistiquées qui étaient auparavant limitées par les ressources, et rendent la fraude automatisée accessible aux attaquants peu qualifiés.
Menaces agentiques pour les équipes sécurité :
- Tentatives automatisées de prise de contrôle de comptes
- Découverte de vulnérabilités assistée par IA
- Abus des flux d'utilisateurs authentifiés
- Manipulation scriptée du processus de paiement
Menaces agentiques pour les équipes fraude :
- Test d'identifiants volés à grande échelle
- Abus de codes promo et de coupons
- Automatisation des workflows de fraude aux retours
- Faux profils créés avec des pièces d'identité et des photos générées par des LLM
Menaces agentiques pour les équipes e-commerce :
- Accaparement de stocks par des acheteurs automatisés
- Scraping de prix
- Fraude aux liens d'affiliation
Comment bloquer les agents IA sur votre site web (étape par étape)
Étape 1 : Identifier les agents IA sur votre site web (qui sont-ils)
Avec un outil de détection :
- Pour obtenir instantanément un tableau de bord des agents IA frauduleux et du trafic de crawlers, vous pouvez utiliser cside Agent Detection.
- Si votre site web est connecté à Cloudflare, vous pouvez consulter leur tableau de bord Bot Analytics pour une ventilation du trafic de crawlers IA.
- Pour une visibilité spécifique au SEO sur le trafic de crawlers IA, vous pouvez utiliser l'analyseur de logs de Screaming Frog. Cet outil analysera vos logs serveur bruts et visualisera un rapport de trafic.
En autonomie :
Si un crawler IA s'identifie publiquement, il affichera des signaux identifiables au niveau de la requête. Vérifiez les chaînes user-agent présentes dans les requêtes HTTP. Pour accéder à ces informations, vous devrez consulter vos logs serveur et rechercher les champs qui correspondent aux identités d'agents IA :
- GPTBot
- ChatGPT-User
- ClaudeBot
Étape 2 : Comprendre les actions des agents IA sur votre site (que font-ils)
Avec un outil de détection spécialisé : Les plateformes de gouvernance d'agents IA comme cside AI Agent Detection ou HUMAN Agentic Trust surveillent l'exécution dans le navigateur, les flux de navigation et les schémas comportementaux. Cela fait passer l'analyse de « est-ce un bot ? » à « qu'est-ce que ce bot cherche à accomplir ? ». Une couche de détection moderne permettra de voir :
- Si un agent déclenche des workflows de connexion ou de paiement
- Les tentatives répétées contre des endpoints sensibles
- Les soumissions automatisées de formulaires
En autonomie : Découvrir manuellement ce que font les agents IA nécessite d'analyser les logs serveur, le timing des requêtes et les schémas d'exécution JavaScript.
Étape 3 : Comprendre l'intention des agents IA (représentent-ils un risque)
Comprendre l'intention des agents IA nécessite de distinguer l'automatisation utile de l'automatisation nuisible. Les outils de détection de bots traditionnels n'ont pas été conçus pour gérer des agents qui imitent le comportement humain et s'exécutent depuis l'environnement de navigateur d'un utilisateur authentique.
Avec un outil de détection spécialisé : Des solutions comme cside AI Agent Detection ou la plateforme Agent Trust de DataDome ont été conçues pour l'internet agentique. Elles vous aident à distinguer les agents IA grand public qui assistent dans la recherche et les achats des agents IA frauduleux qui abusent des codes promo, scrapent des informations ou créent de faux profils.
Plutôt que de prendre des décisions binaires sur l'identité, ces plateformes utilisent des règles avancées de scoring de risque créées par des ingénieurs en sécurité. Celles-ci analysent des signaux tels que :
- Les requêtes excessives ou anormales
- L'utilisation de VPN ou de proxies
- Les environnements d'exécution de navigateur suspects
- Le fingerprinting pour détecter la réutilisation d'appareils dans des workflows à risque (comme l'utilisation de codes promo)
- Les interactions et l'analyse comportementale
Étape 4 : Gouverner les agents IA en fonction du comportement (bloquer, faire confiance ou guider)
Une fois que vous comprenez ce que font les agents IA sur votre site, vous pouvez décider comment les laisser interagir avec votre site web. La réaction instinctive est de tout bloquer sauf les crawlers qui aident au SEO ou à la recherche IA. Cette approche est bonne pour la sécurité, mais exclut les agents IA légitimes qui pourraient rechercher des produits, réserver des billets, remplir des formulaires ou soumettre des demandes.
C'est pourquoi la détection de bots traditionnelle est insuffisante à l'ère agentique. Elle vous offre une logique basique d'autorisation/refus. L'ère agentique exige plus de nuance. Les « bots » agentiques seront créés par les consommateurs au quotidien, omniprésents dans la navigation sur internet. Une stratégie de gouvernance agentique mature détermine « que doit être autorisé à faire cette session agentique ? ».
Par exemple :
- Les agents de recherche peuvent n'avoir besoin que d'un accès en lecture seule à votre site
- Les agents orientés tâches peuvent être autorisés à soumettre des formulaires ou à demander des informations
- Ces mêmes agents orientés tâches peuvent se voir révoquer leurs autorisations d'action sur des pages sensibles comme les portails de gestion de profil
Des plateformes comme cside AI Agent Detection prennent en charge ce type de gouvernance basée sur le comportement. Les tableaux de bord permettent aux équipes fraude d'obtenir facilement des données pour stopper rapidement les abus d'agents IA. Les développeurs disposent d'un SDK et de bibliothèques pour personnaliser l'expérience des agents basés sur navigateur, favorisant ainsi le commerce agentique.
Pourquoi robots.txt ne suffit pas pour bloquer les agents IA
robots.txt est une directive volontaire, pas un contrôle de sécurité. Il demande aux crawlers spécifiés de ne pas accéder à votre site, mais ne les en empêche pas techniquement. robots.txt peut être un mécanisme utile pour bloquer les principaux crawlers (Meta, ChatGPT, GoogleBot) qui s'engagent à respecter cette directive, mais il ne fait pas grand-chose pour stopper la fraude par agents IA.
Les assistants IA et les crawlers de recherche ne respectent pas toujours robots.txt
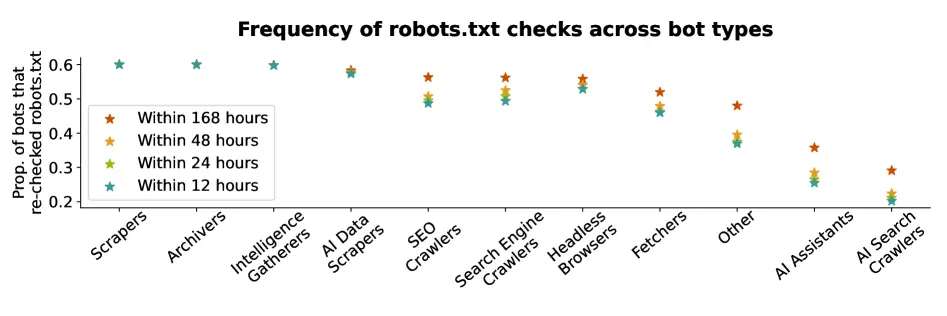
Un rapport de recherche académique de 2025 de l'Université Duke montre que seulement ~60 % des assistants IA et des crawlers de recherche IA consulteront ou respecteront les requêtes « disallow » de robots.txt. Cette moyenne est probablement tirée vers le haut par les bots de ChatGPT et GoogleBot qui respectent la directive à plus de 99 % du temps.
Certains bots populaires comme Perplexity ne respecteront la directive « disallow » qu'environ 20 % du temps.
Les agents IA utilisant des navigateurs headless (comme les agents personnalisés créés par les consommateurs) respectent robots.txt le moins, en se conformant aux directives « disallow » environ 10 % du temps.
Usurpation de user-agent pour contourner robots.txt
robots.txt repose sur des « chaînes user-agent » auto-déclarées. C'est comme se faire demander son nom. Vous pouvez vous déclarer sous n'importe quel nom. Si vous essayez d'entrer à un événement et que vous savez que le nom « Brad Pitt » figure sur la liste, vous pouvez prétendre que c'est votre nom. Dans le monde réel, on pourrait vous demander une preuve. En revanche, robots.txt n'a aucun moyen de confirmer que les identités sont réellement valides.
Ainsi, des agents frauduleux peuvent se faire passer pour « Claudebot » ou « GPTBot ». Si ces identités sont autorisées sur votre site, robots.txt les laissera passer sans problème.
La détection de bots traditionnelle (comme Cloudflare) rate les agents IA
Les systèmes de détection de bots traditionnels ont été conçus pour une époque où l'automatisation s'exécutait depuis des serveurs cloud ou des réseaux de proxies évidents. Ces systèmes s'appuient fortement sur des signaux de couche réseau et des bases de données de réputation, avec une visibilité limitée sur l'exécution JavaScript et les interactions avec le site web.
L'essor de l'automatisation basée sur navigateur hébergée localement
Une catégorie croissante d'automatisation s'exécute désormais dans de véritables environnements de navigateur :
- Les agents grand public qui s'exécutent sur des extensions de navigateur comme Manus ou l'extension navigateur de Claude
- Les automatisations créées par des développeurs qui utilisent des outils de navigateur headless comme Playwright ou Selenium, s'exécutant sur des machines ou même des appareils mobiles
- Les acteurs frauduleux utilisant des outils de navigateur headless open source pour mener des attaques
Cette catégorie d'agents est apparue en partie pour faciliter la création par des consommateurs et développeurs légitimes de bots IA interagissant avec le web. Elle est également apparue comme un effort délibéré pour éviter la détection par les outils de gouvernance de bots traditionnels.
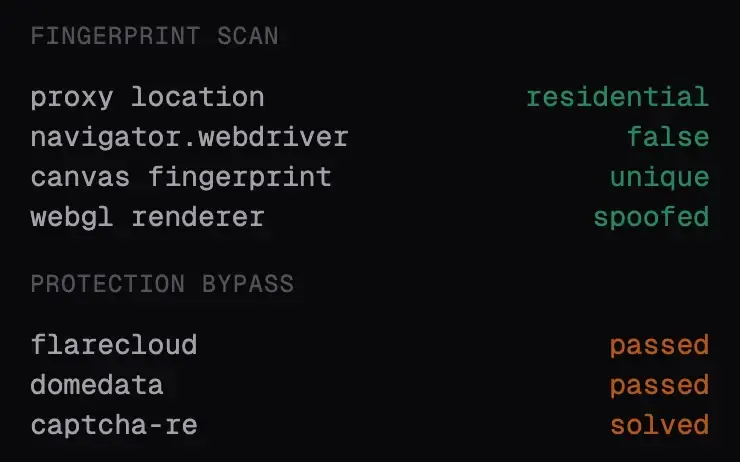
Ces agents basés sur navigateur headless ne s'identifient pas clairement. En réalité, ils cherchent délibérément à ressembler à un vrai utilisateur humain — ce qui rend la détection de fraude plus difficile (et pollue les analyses au passage).
Détecter les agents basés sur navigateur headless nécessite un outil spécialisé de détection d'agents IA qui analyse les signaux comportementaux et le contexte navigateur en profondeur**.**
Comment cside aide les entreprises à bloquer les attaquants agentiques
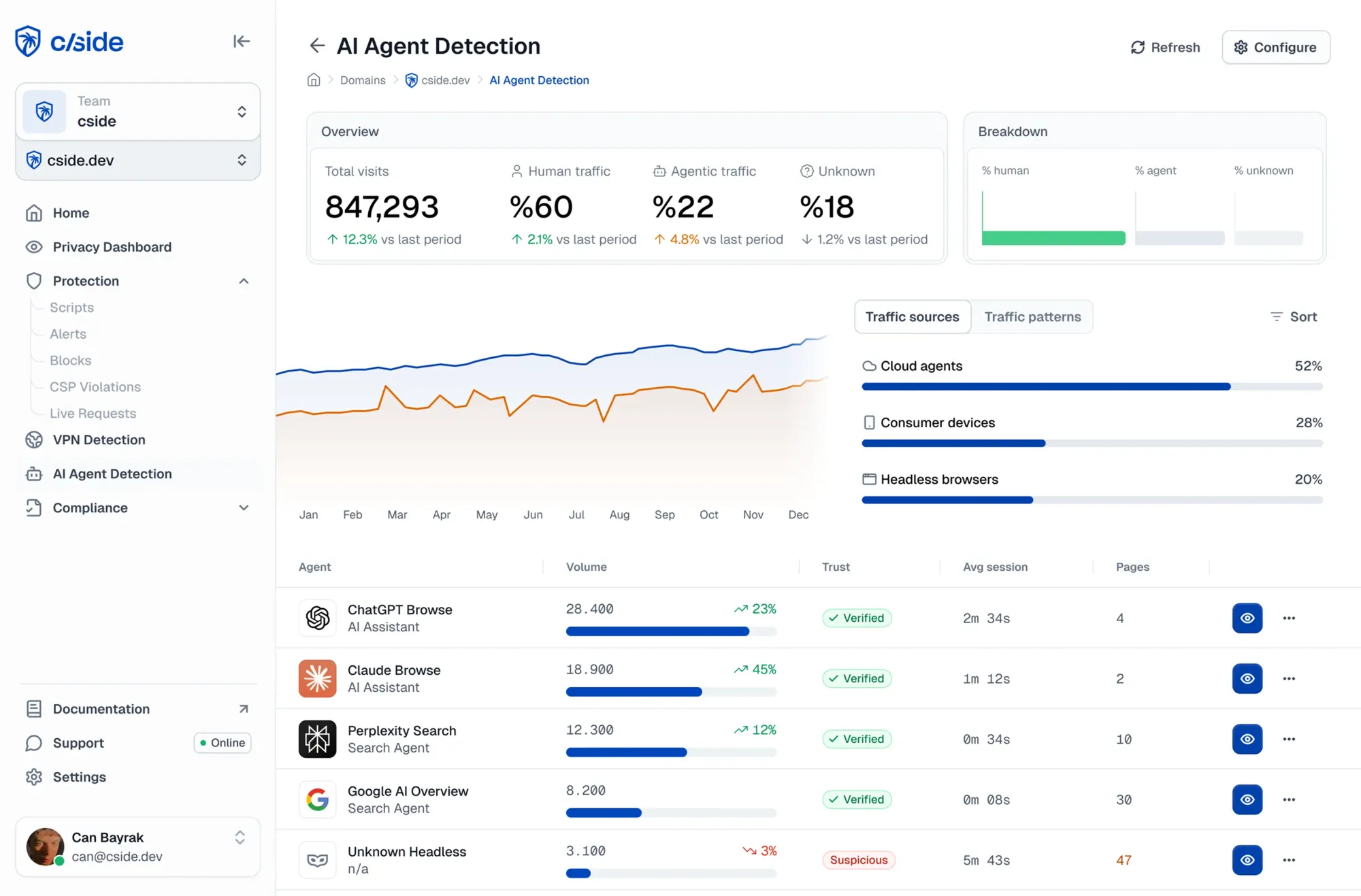
cside est une plateforme de sécurité web spécialisée dans la surveillance des signaux au niveau du navigateur pour réduire la fraude pour les entreprises. cside AI Agent Detection vous aide à identifier, classifier et gouverner le trafic agentique sur votre site web.
- Obtenez un tableau de bord des agents qui accèdent à votre site et de ce qu'ils font
- Scores de risque automatiques basés sur des signaux comportementaux pour détecter les mauvais agents IA (y compris ceux basés sur navigateur et hébergés localement) qui contournent les défenses anti-bots traditionnelles
- Donnez à vos développeurs des outils pour mettre des garde-fous autour de ce que les agents peuvent faire
- Prévenez la fraude par agents IA telle que l'abus de codes promo, le piratage de contenu, les tests de cartes bancaires, la découverte de vulnérabilités et le scraping avancé.
Vous pouvez commencer à voir le trafic agentique sur votre site web avec un compte gratuit.








