

TL;DR
- Robots.txt is een vrijwillige richtlijn, geen beveiligingsmaatregel. AI-agents en crawlers hoeven je verzoek niet na te leven.
- Robots.txt laat ook een achterdeurtje open voor user-agent spoofing, waarbij kwaadwillende AI-agents valselijk beweren een vertrouwde agent te zijn, zoals "GPTBot".
- AI-agents die headless browsers gebruiken (soms lokaal gehost) worden steeds populairder en omzeilen traditionele botdetectietools (zoals Cloudflare).
- Gespecialiseerde tools (zoals cside AI Agent Detection) zijn nodig om nauwkeurig te zien wat agents op je website doen en frauduleuze agentactiviteit te voorkomen.
- AI-crawlers en -scrapers zijn niet de enige bedreiging. Je moet ook agents blokkeren die promotiemisbruik, creditcardtesten, contentpiraterij en chargebackfraude uitvoeren.
4 methoden om AI-agents op je website te blokkeren (vergelijking)
<thead>
<tr>
<th>Methode</th>
<th>Hoe het werkt</th>
<th>Effectief tegen:</th>
<th>Beveiliging/antifraude diepgang:</th>
<th>Kosten</th>
<th>Implementatiemoeilijkheid</th>
</tr>
</thead>
<tbody>
<tr>
<td><strong>robots.txt</strong></td>
<td>
Een tekstbestand dat je aanmaakt en uploadt naar je website. Het vertelt crawlers welke delen van je website ze niet mogen bezoeken.
</td>
<td>
• AI-zoekcrawlers van grote platforms (Google, ChatGPT)<br>
• AI-scrapers die LLM-modellen trainen
</td>
<td>
<strong>Zwak</strong><br>
• De meeste AI-agents respecteren robots.txt niet<br>
• User-agent spoofing is eenvoudig<br>
• Geen zicht op gedrag<br>
• Ineffectief tegen kwaadwillende of lokaal gehoste agents
</td>
<td>Gratis</td>
<td>Eenvoudig. Kan worden geïmplementeerd door niet-technische teams.</td>
</tr>
<tr>
<td><strong>Servermaatregelen</strong></td>
<td>
Stel regels in op serverniveau om agents te blokkeren op basis van IP of user-agent-richtlijnen.
</td>
<td>
• AI-zoekcrawlers van grote platforms (Google, ChatGPT)<br>
• AI-scrapers die LLM-modellen trainen
</td>
<td>
<strong>Zwak</strong><br>
• IP-gebaseerde blokkering kan worden omzeild met residentiële proxies<br>
• HTTP-headers kunnen worden gespoofed<br>
• Vereist handmatige configuratie die snel fout kan gaan
</td>
<td>Laag tot gemiddeld (vereist tijd van personeel)</td>
<td>Gemiddeld. Vereist ondersteuning van een ontwikkelaar of DevOps</td>
</tr>
<tr>
<td><strong>Traditionele botdetectie (zoals Cloudflare)</strong></td>
<td>
Leverancierstool met dashboards. Kent botscores toe op basis van netwerklaagsignalen, reputatiedatabases en beperkte client-side monitoring.
</td>
<td>
• AI-zoekcrawlers<br>
• AI-scrapers die LLM-modellen trainen<br>
• Eenvoudige bots en scrapers<br>
• DDoS-aanvallen
</td>
<td>
<strong>Gemiddeld</strong><br>
• Moeite met lokaal gehoste browseragents<br>
• Beperkt zicht op interactieniveau<br>
• Binaire toestaan/weigeren-logica<br>
• Zwakke governancemogelijkheden
</td>
<td>Laag tot gemiddeld (afhankelijk van prijsplan)</td>
<td>Eenvoudig.</td>
</tr>
<tr>
<td><strong>Gespecialiseerde AI-agentdetectie (zoals cside)</strong></td>
<td>
Leverancierstool met dashboards. Kijkt naar gedragsuitvoering, diepgaande client-side monitoring en unieke signalen om AI-agents nauwkeuriger te herkennen.
</td>
<td>
• AI-zoekcrawlers van grote platforms (Google, ChatGPT)<br>
• AI-scrapers die LLM-modellen trainen<br>
• Eenvoudige bots en scrapers<br>
• Consumer-agents die draaien als browserextensies<br>
• Frauduleuze AI-agents (lokaal gehoste omgevingen, headless browsers)
</td>
<td>
<strong>Sterk</strong><br>
• Speciaal gebouwd om AI-agents te weren<br>
• Combineert netwerk-, applicatie- en interactieniveausignalen<br>
* Nauwkeurigere detectie van agents op basis van headless browsers
</td>
<td>Laag tot gemiddeld (afhankelijk van prijsplan)</td>
<td>Eenvoudig. Installeer een stukje code op je website.</td>
</tr>
</tbody>
</table>
1. Robots.txt
Hoe het werkt: Je maakt een "robots.txt"-bestand aan en uploadt dit naar je website. Dit tekstbestand bevat een lijst met namen van AI-agents die wel of niet zijn toegestaan. Wanneer die agents je website bezoeken en lezen dat ze "disallowed" zijn, zullen ze afzien van toegang tot je site.*
* Alleen agents die ervoor kiezen je robots.txt te respecteren, worden daadwerkelijk geweerd. Dit bestand kan worden genegeerd door kwaadwillende of verkeerd geconfigureerde agents.
Vereenvoudigd voorbeeld
# Allow OpenAI's crawler (ChatGPT / GPTBot)
User-agent: GPTBot
Allow: /
## Disallow DeepSeek's crawler
User-agent: DeepSeekBot
Disallow: /
Codeblok: Voorbeeld van een robots.txt-richtlijn die GPTBot toestaat en DeepSeekBot blokkeert
De meeste robots.txt-bestanden bevatten tientallen user-agent-richtlijnen.
Voordelen
- Gratis
- Veel tools en sjablonen om snel aan de slag te gaan
- Kan binnen een dag worden ingesteld
- Kan worden geïmplementeerd door een niet-technisch persoon
Beperkingen
- Agents zijn niet verplicht je robots.txt-bestand te respecteren. Het is meer een beleefd verzoek. Crawlers van grote AI-aanbieders (Meta, Anthropic, OpenAI) respecteren deze richtlijnen doorgaans, maar deze bedrijven zijn slechts het topje van de ijsberg van alle AI-agents.
- Kwaadwillende AI-agents negeren je robots.txt-bestand.
- Handmatig onderhoud voor honderden populaire AI-agenttools, elk met meerdere agentidentiteiten (crawler, onderzoek, actievoerder).
- Niet alle AI-agents hebben een publieke "identiteit". Platforms zoals Selenium en Playwright stellen gebruikers in staat agents te maken die je website bezoeken zonder duidelijke identiteit.
- Je hebt nul zicht op gedrag. Dit mechanisme dient slechts als een "blokkeer of niet"-lijst. Je ziet niet hoeveel verkeer agentisch is of wat agents doen.
Moet je robots.txt gebruiken: Ja. Het is een goed startpunt voor kleine bedrijven en beschermt je tegen grote, publiek bekende crawlers zoals Meta die anders serverresources verspillen. Dit mechanisme beschermt je echter niet tegen AI-agentfraude.
2. Servermaatregelen
Hoe het werkt: Je configureert regels op je webserver (.htaccess), CDN of firewall die AI-agents daadwerkelijk blokkeren via:
- Blokkeren van specifieke IP-adressen of -reeksen van bekende agents
- Rate limiting bij buitensporige verzoekpatronen
- Inspecteren van HTTP-headers
- Controleren van user-agent-identiteiten (vergelijkbaar met robots.txt)
Anders dan robots.txt hebben servermaatregelen echte handhavingskracht. Deze regels blokkeren agents of retourneren een foutcode zodat ze geen toegang krijgen tot je website.
Voordelen
- Echte handhaving tegen agentverkeer
- Vermindert eenvoudige scrapingagents
- Stopt misbruik van grote aantallen verzoeken
- Werkt goed voor het stoppen van publiek geïdentificeerde crawlers (Meta, DeepSeek, Google)
Beperkingen
- Vereist technische configuratie en onderhoud, vaak door een webontwikkelaar
- Kwaadwillende AI-agents kunnen deze maatregelen omzeilen
- IP-gebaseerde blokkering kan worden omzeild door residentiële proxies of roterende IP-adressen
- HTTP-headers kunnen eenvoudig worden gespoofed
- Geen zicht op gedrag. Dit mechanisme blokkeert agents maar geeft geen inzicht in wat agents doen.
Conclusie: Als je technisch personeel hebt, zijn servermaatregelen een krachtige manier om agentcrawlerverzoeken te weigeren. Deze methode schiet echter tekort bij het verdedigen tegen AI-agentfraude of AI-ondersteunde websiteaanvallen, omdat kwaadwillende agents valse identiteiten kunnen aanmaken en verificatiecontroles kunnen passeren.
3. Traditionele botdetectietools (bijv. Cloudflare)
Veel traditionele botdetectieproducten hebben hun branding bijgewerkt naar 'AI-agentdetectie', maar hebben hun daadwerkelijke product onvoldoende doorontwikkeld en slagen er niet in lokaal gehoste browsers of agentomgevingen te detecteren die zijn gebouwd om detectie te vermijden.
Hoe het werkt: Leverancierstools zoals Cloudflare botdetectie kennen elke bezoeker een "botscore" toe op basis van gedragsanalyse, vingerafdrukken, reputatiedatabases van bekende bedreigingen en andere signalen.
Deze leverancierstools werken voornamelijk op de CDN- of netwerklaag van je website, met enige JavaScript-injectie op webpagina's om browsersignalen te verzamelen (client-side monitoring).
Voordelen
- Relatief eenvoudig te installeren
- Kijkt vergeleken met toestaan/weigeren-lijsten naar meer geavanceerde signalen dan alleen identiteit
- Bewezen bescherming tegen aanvallen zoals DDoS en eenvoudige scrapingbots
- Meer geautomatiseerd dan handmatige servermaatregelen
Beperkingen
- Kan worden omzeild door frauduleuze AI-agents die menselijk gedrag nabootsen
- Moeite met het detecteren van lokaal gehoste browseragents, die steeds vaker worden gebruikt door consumenten en aanvallers
- Vertrouwt op applicatieniveausignalen, met zeer beperkte interactieniveausignalen
- Geen mogelijkheid om consumer-AI-agents te begeleiden in het aankooptraject
- Beperkt zicht op client-side signalen
Traditionele botdetectietools zijn niet klaar voor AI-agents: Deze oplossingen zijn gebouwd voor een tijdperk waarin bots in cloudinfrastructuur leefden, niet konden redeneren en voorspelbare patronen volgden. Moderne AI-agents draaien in echte browsers en gaan op in normaal verkeer. Alles blokkeren stopt voor de hand liggend misbruik, maar een moderne agentgovernancestrategie vereist inzicht in intentie en dynamische regels.
Onze interne tests bij cside konden traditionele botdetectie bij 80 van de 100 pogingen omzeilen met minimale inspanning.
4. Gespecialiseerde AI-agentdetectietools (bijv. cside)
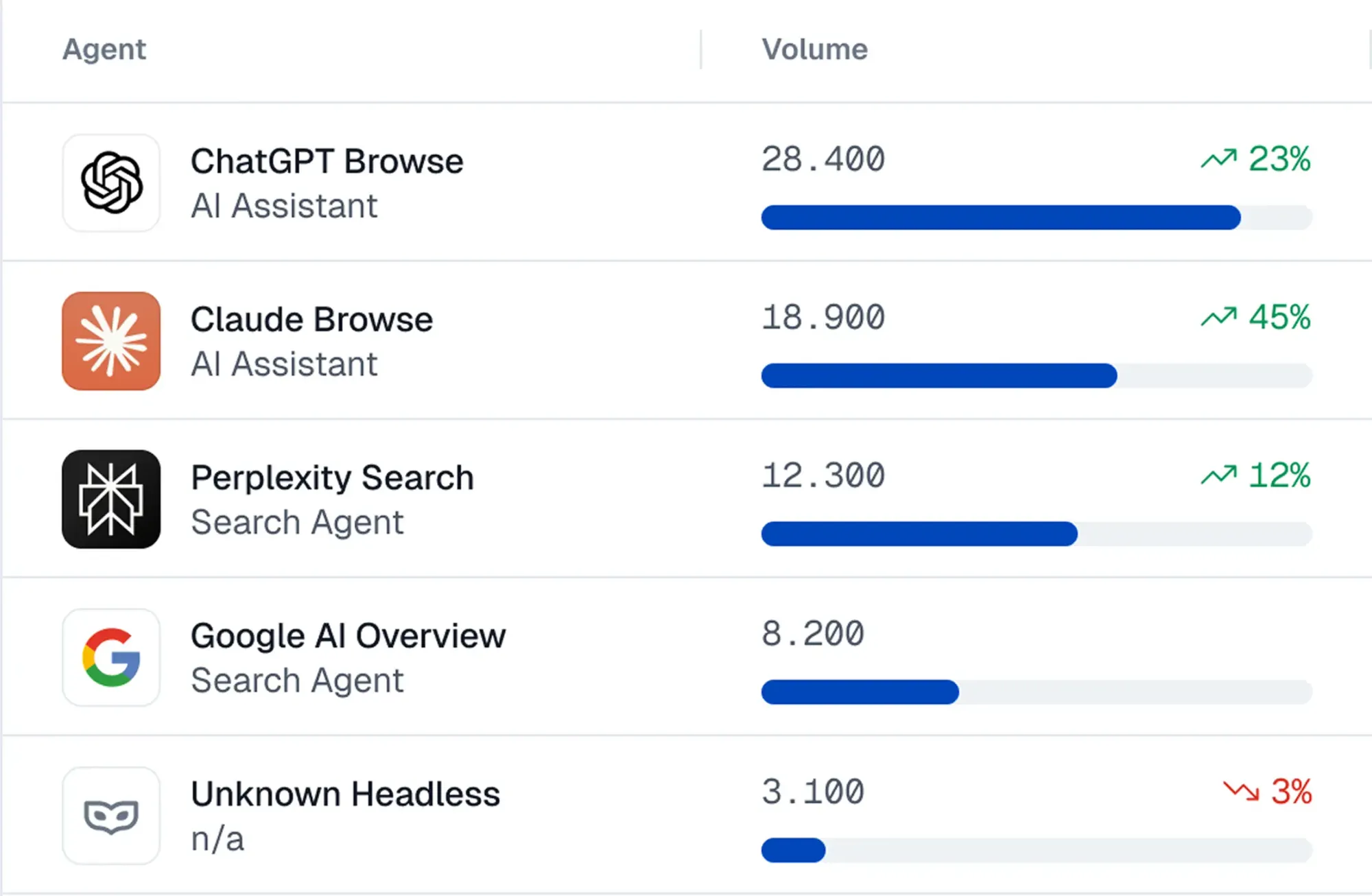
Hoe het werkt: Een stukje code wordt op je site geïnstalleerd, waarmee je controle krijgt over:
- Detectie: Observeer tientallen signalen om AI-agents, hun acties en frauderisico te identificeren.
- Blokkering: Risicoscores worden samengesteld uit een verscheidenheid aan signalen — interactiepatronen, vingerafdrukken, JavaScript-uitvoeringscontext, reputatiedatabases, honeypots en meer. Je kunt agentrisico beoordelen en dynamische regels instellen om agents volledig te blokkeren of beperkte toegang te verlenen.
- Governance: Een SDK wordt door ontwikkelaars gebruikt om guardrails toe te voegen aan agentsessies. Bepaalde stappen kunnen bijvoorbeeld menselijke validatie vereisen, of bepaalde vertrouwde agents kunnen aankopen doen terwijl anderen beperkt zijn tot alleen-lezen modus.
Voordelen
- Eenvoudig te implementeren met dashboards voor fraudeteams en SDK's voor ontwikkelaars
- Speciaal gebouwd voor AI-agents. cside is beter in het detecteren van lokaal gehoste browser-AI-agents (bijv. Playwright, Selenium)
- Sterker in het detecteren van agents die werken vanuit browserextensies (Manus AI, Comet)
- Gebouwd om agentgebaseerde aanvallen en fraude te voorkomen in plaats van alleen "crawlers blokkeren"
- Governancemogelijkheden om agentische commerce-ervaringen te verbeteren
- Zicht op agentisch verkeer. Een dashboard met welke agents op je site zijn, welke acties ze uitvoeren, waar ze vastlopen en welk risico ze met zich meebrengen.
Moderne webbeveiliging heeft een gespecialiseerde AI-agentdetectietool nodig: "Bots" en crawlers blokkeren is niet langer voldoende. AI-agents vereisen gedragsclassificatie en dynamische regels. Tools zoals cside AI Agent Detection geven ondernemingen dit inzicht zodat fraude kan worden geblokkeerd zonder legitieme consumer-agents te hinderen.
Waarom je (sommige) AI-agents van je website moet blokkeren

Niet alle AI-agents zijn schadelijk. Sommige helpen consumenten. Sommige fungeren als onderzoekstools. Maar veel agents zijn frauduleus. Een onderzoeksrapport van Ahrefs stelde vast dat 63% van de websites agentisch verkeer ontvangt. Dat was begin 2025. Inmiddels ligt dat percentage waarschijnlijk hoger.
Waarom crawlers en scrapers blokkeren:
Het gesprek over agentisch verkeer richt zich momenteel op zichtbare crawlers van ChatGPT, Gemini of andere LLM-platforms die content ophalen voor antwoorden of om modellen te trainen. De motivatie om crawlers en scrapers te blokkeren is valide, met name voor bedrijven met unieke content zoals uitgevers of mediastreaming-diensten die te maken hebben met:
- Scraping van premiumcontent voor piraterij
- Harvesten van content om LLM-modellen te trainen zonder toestemming
Waarom frauduleuze AI-agents:
Crawlers van LLM-platforms zijn niet de enige bedreiging. Ze bevinden zich zelfs aan de "veiligere" kant van het botautomatiseringsspectrum. De zorgwekkendere bedreiging is hoe geautomatiseerd misbruik door aanvallers wordt versterkt door AI-agents. Agents maken het eenvoudiger om detectie te vermijden en menselijk gedrag na te bootsen.
Een rapport over financiële criminaliteit van het Amerikaanse Ministerie van Financiën wijst erop hoe AI-agents de drempel verlagen voor geavanceerde aanvalstechnieken die voorheen beperkt waren door middelen, en geautomatiseerde fraude toegankelijk maken voor laaggeschoolde aanvallers.
Agentische bedreigingen voor beveiligingsteams:
- Geautomatiseerde pogingen tot accountovername
- AI-ondersteunde kwetsbaarheidsontdekking
- Misbruik van geauthenticeerde gebruikersstromen
- Gescripte manipulatie van het afrekenproces
Agentische bedreigingen voor fraudeteams:
- Gestolen inloggegevens op grote schaal testen
- Promotiecodes en coupons misbruiken
- Retourfraudeworkflows automatiseren
- Neppe profielen aanmaken met document-ID's en foto's gegenereerd door LLM's
Agentische bedreigingen voor e-commerceteams:
- Voorraadhamsteren door geautomatiseerde kopers
- Prijsscraping
- Affiliatelinkfraude
Hoe je AI-agents op je website blokkeert (stap voor stap)
Stap 1: Identificeer de AI-agents op je website (wie zijn ze)
Met een detectietool:
- Voor een direct dashboard van frauduleuze AI-agents en crawlerverkeer kun je cside Agent Detection gebruiken.
- Als je website is verbonden met Cloudflare kun je hun Bot Analytics-dashboard raadplegen voor een overzicht van AI-crawlerverkeer.
- Voor SEO-specifiek inzicht in AI-crawlerverkeer kun je de loganalyzer van Screaming Frog gebruiken. Deze tool analyseert je ruwe serverlogs en visualiseert een verkeersrapport.
Zelf doen:
Als een AI-crawler zichzelf publiekelijk identificeert, toont het herkenbare signalen op de verzoeklaag. Controleer user-agent-strings in HTTP-verzoeken. Om toegang te krijgen tot deze informatie moet je naar je serverlogs gaan en zoeken naar velden die correleren met AI-agentidentiteiten:
- GPTBot
- ChatGPT-User
- ClaudeBot
Stap 2: Begrijp welke acties AI-agents op je site uitvoeren (wat doen ze)
Met een gespecialiseerde detectietool: AI-agentgovernanceplatforms zoals cside AI Agent Detection of HUMAN Agentic Trust monitoren browseruitvoering, navigatiestromen en gedragspatronen. Dit verschuift de analyse van "is dit een bot?" naar "wat probeert deze bot te bereiken?". Een moderne detectielaag ziet:
- Of een agent inlog- of afrekenworkflows activeert
- Herhaalde pogingen op gevoelige endpoints
- Geautomatiseerde formulierinzendingen
Zelf doen: Handmatig ontdekken wat AI-agents doen vereist het analyseren van serverlogs, verzoektiming en JavaScript-uitvoeringspatronen.
Stap 3: Begrijp de intentie achter AI-agents (vormen ze een risico)
De intentie van AI-agents begrijpen vereist onderscheid maken tussen automatisering die nuttig is en automatisering die schadelijk is. Traditionele botdetectietools zijn niet gebouwd om agents te verwerken die menselijk gedrag nabootsen en draaien vanuit de browseromgeving van een echte gebruiker.
Met een gespecialiseerde detectietool: Oplossingen zoals cside AI Agent Detection of het Agent Trust-platform van DataDome zijn gebouwd voor het agentische internet. Ze helpen je onderscheid te maken tussen consumer-AI-agents die helpen bij onderzoek en winkelen versus frauduleuze AI-agents die promotiecodes misbruiken, informatie scrapen of neppe profielen aanmaken.
In plaats van binaire beslissingen op basis van identiteit gebruiken dergelijke platforms geavanceerde risicoscoreregels die zijn opgesteld door beveiligingsingenieurs. Deze kijken naar signalen zoals:
- Buitensporige of abnormale verzoeken
- Gebruik van VPN's of proxies
- Verdachte browseruitvoeringsomgevingen
- Vingerafdrukken om hergebruik van apparaten te detecteren in risicovolle workflows (zoals inwisseling van promotiecodes)
- Interacties en gedragsanalyse
Stap 4: Beheer AI-agents op basis van gedrag (blokkeren, vertrouwen of begeleiden)
Zodra je begrijpt wat AI-agents op je site doen, kun je bepalen hoe ze met je website mogen omgaan. De reflexmatige reactie is alles blokkeren behalve crawlers die helpen met SEO of AI-zoeken. Die aanpak is goed voor beveiliging, maar sluit legitieme AI-agents buiten die mogelijk producten onderzoeken, tickets boeken, formulieren invullen of vragen indienen.
Dit is waarom traditionele botdetectie tekortschiet in het agentische tijdperk. Ze bieden je basale toestaan/weigeren-logica. Het agentische tijdperk vereist meer nuance. Agentische "bots" worden dagelijks door consumenten aangemaakt en zijn alomtegenwoordig bij het navigeren op internet. Een volwassen agentische governancestrategie bepaalt: "wat mag deze agentische sessie doen?"
Bijvoorbeeld:
- Onderzoeksagents hebben mogelijk alleen leestoegang tot je website nodig
- Taakgebaseerde agents mogen formulieren indienen of informatie opvragen
- Diezelfde taakgebaseerde agents kunnen hun toestemming voor acties ingetrokken zien op gevoelige pagina's zoals profielbeheerportalen
Platforms zoals cside AI Agent Detection ondersteunen dit soort gedragsgebaseerde governance. Dashboards maken het fraudeteams eenvoudig om gegevens te krijgen om AI-agentmisbruik vroegtijdig te stoppen. Ontwikkelaars krijgen een SDK en bibliotheken om de ervaring voor browsergebaseerde agents aan te passen, wat agentische commerce verder mogelijk maakt.
Waarom robots.txt niet genoeg is om AI-agents te blokkeren
robots.txt is een vrijwillige richtlijn, geen beveiligingsmaatregel. Het verzoekt bepaalde crawlers je site niet te bezoeken, maar verhindert dit technisch gezien niet. Robots.txt kan een nuttig mechanisme zijn om grote crawlers (Meta, ChatGPT, GoogleBot) te blokkeren die beloven deze richtlijn te respecteren, maar het doet weinig om AI-agentfraude te stoppen.
AI-assistenten en zoekcrawlers voldoen niet altijd aan robots.txt
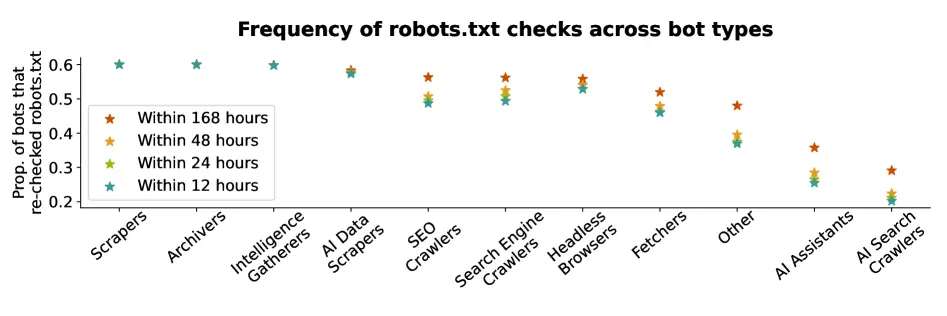
Een academisch onderzoeksrapport uit 2025 van Duke University toont aan dat slechts ~60% van de AI-assistenten en AI-zoekcrawlers 'disallow'-verzoeken in robots.txt bekijkt of naleeft. Dat gemiddelde wordt waarschijnlijk omhoog getrokken door bots van ChatGPT en GoogleBot die de richtlijn 99%+ van de tijd respecteren.
Sommige populaire bots zoals Perplexity respecteren de 'disallow'-richtlijn slechts ~20% van de tijd.
AI-agents die headless browsers gebruiken (zoals op maat gemaakte agents gemaakt door consumenten) respecteren robots.txt het minst, met naleving van 'disallow'-richtlijnen van slechts ~10% van de tijd.
User-agent spoofing om robots.txt te omzeilen
robots.txt is gebaseerd op zelf opgegeven "user-agent strings". Het is alsof je wordt gevraagd wat je naam is. Je kunt zelf opgeven wat je maar wilt. Als je een evenement wilt binnenkomen en je weet dat de naam "Brad Pitt" op de lijst staat, kun je zeggen dat dat jouw naam is. In de echte wereld word je mogelijk gevraagd bewijs te tonen. robots.txt heeft daarentegen geen manier om te bevestigen dat identiteiten daadwerkelijk geldig zijn.
Frauduleuze agents kunnen dus beweren "Claudebot" of "GPTBot" te zijn. Als die identiteiten zijn toegestaan op je site, laat robots.txt ze gewoon door.
Traditionele botdetectie (zoals Cloudflare) mist AI-agents
Traditionele botdetectiesystemen zijn ontworpen voor een tijdperk waarin automatisering draaide op cloudservers of voor de hand liggende proxynetwerken. Deze systemen vertrouwen sterk op netwerklaagsignalen en reputatiedatabases met beperkt zicht op JavaScript-uitvoering en websiteinteracties.
De opkomst van lokaal gehoste, browsergebaseerde automatisering
Een groeiende categorie automatisering draait nu in echte browseromgevingen:
- Consumer-agents die draaien als browserextensies zoals Manus of de browserextensie van Claude
- Automatiseringen gemaakt door ontwikkelaars die headless browsertechnologieën zoals Playwright of Selenium gebruiken op machines of zelfs mobiele apparaten
- Frauduleuze actoren die open source headless browsertechnologieën gebruiken om aanvallen uit te voeren
Deze categorie agents is deels ontstaan om het voor legitieme consumenten en ontwikkelaars eenvoudig te maken AI-bots te bouwen die met het web communiceren. Het is ook bewust ontstaan als poging om detectie door traditionele botgovernancetools te vermijden.
Deze headless browsergebaseerde agents identificeren zichzelf niet duidelijk. Ze proberen er juist opzettelijk uit te zien als een echte menselijke gebruiker — wat fraudedetectie moeilijker maakt (en tegelijkertijd analyses vergiftigt).
Het opsporen van headless browsergebaseerde agents vereist een gespecialiseerde AI-agentdetectietool die kijkt naar gedragssignalen en diepgaande browsercontext.
Hoe cside ondernemingen helpt agentische aanvallers te blokkeren
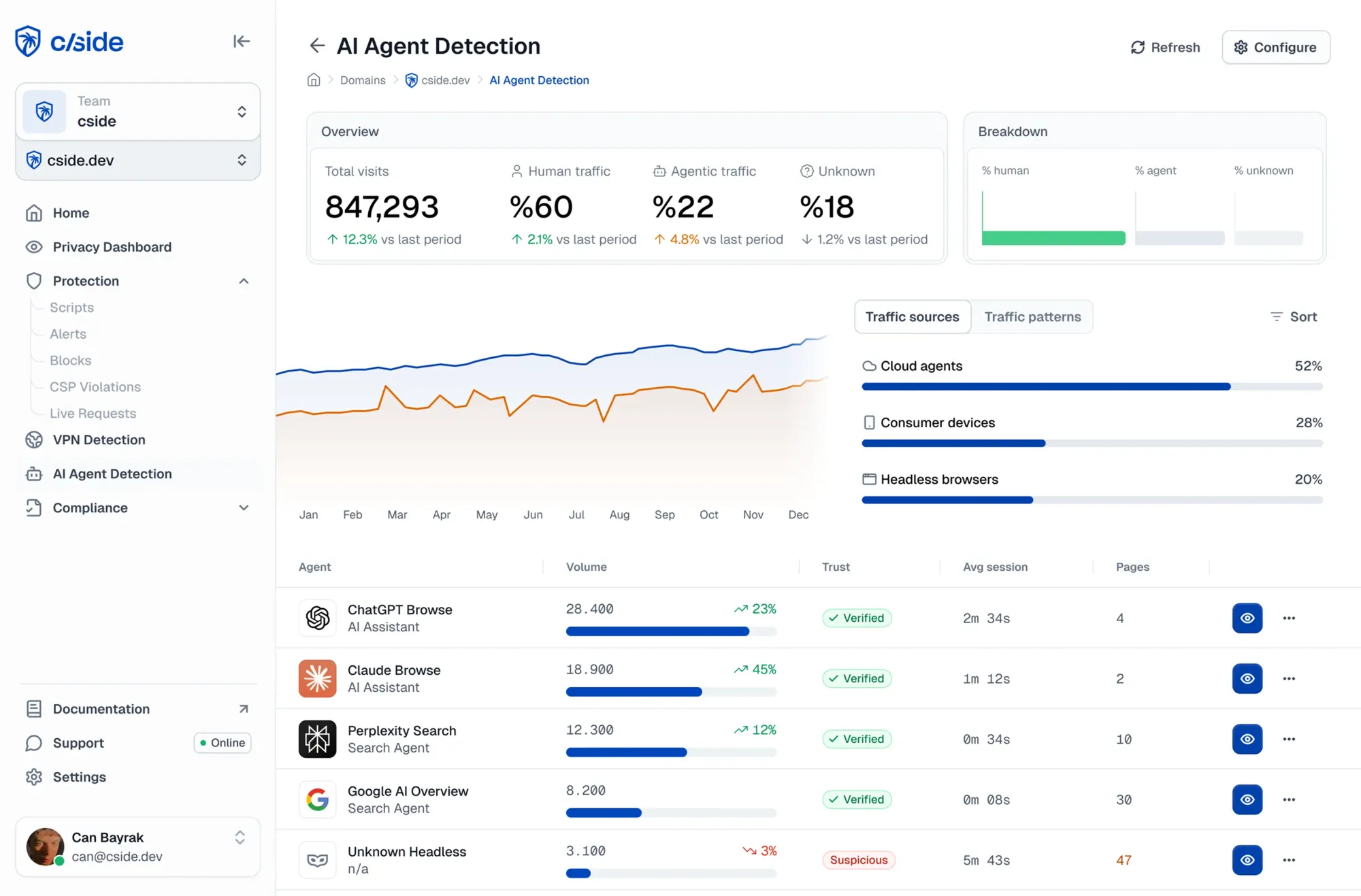
cside is een webbeveiligingsplatform, gespecialiseerd in het monitoren van browserlaagsignalen om fraude voor ondernemingen te verminderen. cside AI Agent Detection helpt je agentisch verkeer op je website te identificeren, classificeren en beheren.
- Krijg een dashboard van welke agents toegang hebben tot je site en wat ze doen
- Automatische risicoscores op basis van gedragssignalen om slechte AI-agents te detecteren (inclusief browsergebaseerde en lokaal gehoste) die traditionele botbeveiliging omzeilen
- Geef je ontwikkelaars tools om guardrails te plaatsen rondom wat agents kunnen doen
- Voorkom AI-agentfraude zoals misbruik van promotiecodes, contentpiraterij, creditcardtesten, kwetsbaarheidsontdekking en geavanceerde scraping
Je kunt beginnen met het bekijken van agentisch verkeer op je website met een gratis account.








