

TL; DR
- robots.txt es una directiva voluntaria, no un control de seguridad. Los agentes de IA y los rastreadores no están obligados a cumplir con tu solicitud.
- robots.txt también deja una puerta abierta para la suplantación de user-agent, cuando agentes de IA maliciosos declaran falsamente ser un agente de confianza como "GPTBot".
- Los agentes de IA que usan navegadores headless (a veces alojados localmente) son cada vez más populares y eluden las herramientas de detección de bots heredadas (como Cloudflare).
- Se necesitan herramientas especializadas (como cside AI Agent Detection) para ver con precisión qué hacen los agentes en tu sitio web y prevenir la actividad fraudulenta de agentes.
- Los rastreadores y scrapers de IA no son la única amenaza. Deberías bloquear a los agentes que ejecutan abuso de promociones, prueba de tarjetas de crédito, piratería de contenido y fraude de contracargos.
4 métodos para bloquear agentes de IA en tu sitio web (comparativa)
<thead>
<tr>
<th>Método</th>
<th>Cómo funciona</th>
<th>Eficaz contra:</th>
<th>Profundidad de seguridad/antifraude:</th>
<th>Coste</th>
<th>Dificultad de implementación</th>
</tr>
</thead>
<tbody>
<tr>
<td><strong>robots.txt</strong></td>
<td>
Un archivo de texto que creas y subes a tu sitio web. Indica a los rastreadores qué partes de tu sitio no deben acceder.
</td>
<td>
• Rastreadores de IA de las principales plataformas (Google, ChatGPT)<br>
• Scrapers de IA que entrenan modelos LLM
</td>
<td>
<strong>Débil</strong><br>
• La mayoría de los agentes de IA no respetan robots.txt<br>
• La suplantación de user-agent es sencilla<br>
• Sin visibilidad sobre el comportamiento<br>
• Ineficaz contra agentes maliciosos o alojados localmente
</td>
<td>Gratuito</td>
<td>Fácil. Puede ser implementado por equipos no técnicos.</td>
</tr>
<tr>
<td><strong>Controles del servidor</strong></td>
<td>
Configura reglas a nivel de servidor para bloquear agentes según IP o directivas de user-agent.
</td>
<td>
• Rastreadores de IA de las principales plataformas (Google, ChatGPT)<br>
• Scrapers de IA que entrenan modelos LLM
</td>
<td>
<strong>Débil</strong><br>
• El bloqueo por IP puede eludirse con proxies residenciales<br>
• Las cabeceras HTTP pueden suplantarse<br>
• Requiere configuración manual que puede estar mal configurada fácilmente
</td>
<td>Bajo a moderado (requiere tiempo del personal)</td>
<td>Medio. Requiere soporte de un desarrollador o DevOps.</td>
</tr>
<tr>
<td><strong>Detección de bots tradicional (como Cloudflare)</strong></td>
<td>
Herramienta de proveedor con paneles de control. Asigna puntuaciones de bot usando señales de la capa de red, bases de datos de reputación y monitorización limitada del lado del cliente.
</td>
<td>
• Rastreadores de IA de búsqueda<br>
• Scrapers de IA que entrenan modelos LLM<br>
• Bots y scrapers básicos<br>
• Ataques DDoS
</td>
<td>
<strong>Media</strong><br>
• Tiene dificultades con agentes de navegador alojados localmente<br>
• Visibilidad limitada a nivel de interacción<br>
• Lógica binaria de permitir/denegar<br>
• Capacidades de gobernanza débiles
</td>
<td>Bajo a moderado (depende del plan de precios)</td>
<td>Fácil.</td>
</tr>
<tr>
<td><strong>Detección especializada de agentes de IA (como cside)</strong></td>
<td>
Herramienta de proveedor con paneles de control. Analiza la ejecución del comportamiento, la monitorización profunda del lado del cliente y señales únicas para identificar agentes de IA con mayor precisión.
</td>
<td>
• Rastreadores de IA de las principales plataformas (Google, ChatGPT)<br>
• Scrapers de IA que entrenan modelos LLM<br>
• Bots y scrapers básicos<br>
• Agentes de consumidor que se ejecutan en extensiones de navegador<br>
• Agentes de IA fraudulentos (entornos alojados localmente, navegadores headless)
</td>
<td>
<strong>Sólida</strong><br>
• Diseñada específicamente para defenderse de agentes de IA<br>
• Combina señales a nivel de red, aplicación e interacción<br>
* Detección más precisa contra agentes basados en navegadores headless
</td>
<td>Bajo a moderado (depende del plan de precios)</td>
<td>Fácil. Instala un fragmento de código en tu sitio web.</td>
</tr>
</tbody>
</table>
1. Robots.txt
Cómo funciona: Creas un archivo "robots.txt" que subes a tu sitio web. Este archivo de texto contiene una lista de nombres de agentes de IA que están permitidos o no permitidos. Cuando esos agentes visitan tu sitio web y leen que están "no permitidos", se abstendrán de acceder a tu sitio. *
* Solo los agentes que elijan respetar tu robots.txt serán efectivamente bloqueados. Los agentes maliciosos o mal configurados pueden ignorar este archivo.
Ejemplo simplificado
# Allow OpenAI's crawler (ChatGPT / GPTBot)
User-agent: GPTBot
Allow: /
## Disallow DeepSeek's crawler
User-agent: DeepSeekBot
Disallow: /
Bloque de código: Ejemplo de directiva robots.txt que permite GPTBot y bloquea DeepSeekBot
La mayoría de los archivos robots.txt contendrán docenas de directivas de user-agent.
Ventajas
- Gratuito
- Muchas herramientas y plantillas para empezar rápidamente
- Puede configurarse en un día
- Puede implementarlo una persona sin conocimientos técnicos
Limitaciones
- Los agentes no están obligados a respetar tu archivo robots.txt. Es más bien una solicitud educada. Los rastreadores de los principales proveedores de IA (Meta, Anthropic, OpenAI) tienden a respetar estas directivas, pero estas empresas son solo la punta del iceberg del total de agentes de IA.
- Los agentes de IA maliciosos ignorarán tu archivo robots.txt.
- Mantenimiento manual para cientos de herramientas de agentes de IA populares, cada una con múltiples identidades agénticas (rastreador, investigación, ejecutores de acciones).
- No todos los agentes de IA tienen una "identidad" pública. Plataformas como Selenium y Playwright permiten a los usuarios crear agentes que acceden a tu sitio web sin una identidad clara.
- Tienes visibilidad cero sobre el comportamiento. Este mecanismo sirve únicamente como una lista de "bloquear o no". No ves cuánto tráfico es agéntico ni qué hacen los agentes.
¿Deberías usar robots.txt? Sí. Es un excelente punto de partida para pequeñas empresas y te protegerá de los principales rastreadores conocidos públicamente, como Meta, que de otro modo consumirían recursos del servidor. Sin embargo, este mecanismo no te protegerá del fraude de agentes de IA.
2. Controles del servidor
Cómo funciona: Configuras reglas en tu servidor web (.htaccess), CDN o firewall que bloquean activamente a los agentes de IA mediante:
- Bloqueo de direcciones IP específicas o rangos de agentes conocidos
- Limitación de velocidad en patrones de solicitudes excesivas
- Inspección de cabeceras HTTP
- Análisis de identidades de user-agent (similar a robots.txt)
A diferencia de robots.txt, los controles del servidor tienen poder de aplicación real. Estas reglas bloquearán a los agentes o devolverán un código de error para que no puedan acceder a tu sitio web.
Ventajas
- Aplicación real contra el tráfico de agentes
- Mitiga agentes de scraping simples
- Detiene el abuso de solicitudes de alto volumen
- Funciona bien para detener rastreadores identificados públicamente (Meta, DeepSeek, Google)
Limitaciones
- Requiere configuración técnica y mantenimiento, a menudo por parte de un desarrollador web
- Los agentes de IA maliciosos pueden eludir estos controles
- El bloqueo basado en IP puede ser evitado por proxies residenciales o IPs rotativas
- Las cabeceras HTTP pueden suplantarse fácilmente
- Sin visibilidad sobre el comportamiento. Este mecanismo bloqueará agentes pero no te dará información sobre lo que están haciendo.
Conclusión: Si cuentas con personal técnico, los controles del servidor son una forma sólida de aplicar denegaciones contra las solicitudes de rastreadores de agentes. Este método sigue siendo insuficiente para defenderse del fraude de agentes de IA o de los ataques asistidos por IA a sitios web, ya que los agentes maliciosos pueden crear identidades falsas y superar los controles de verificación.
3. Herramientas de detección de bots tradicionales (p. ej., Cloudflare)
Muchos productos de detección de bots heredados actualizaron su marca a 'detección de agentes de IA', pero no han evolucionado su producto real lo suficiente y no logran detectar navegadores alojados localmente ni entornos agénticos diseñados para evitar la detección.
Cómo funciona: Herramientas de proveedores como la detección de bots de Cloudflare asignan a cada visitante una "puntuación de bot" basada en análisis de comportamiento, huellas digitales, bases de datos de reputación de amenazas conocidas y otras señales.
Estas herramientas de proveedores operan principalmente en la capa CDN o de red de tu sitio web, con cierta inyección de JavaScript en las páginas web para recopilar señales del navegador (monitorización del lado del cliente).
Ventajas
- Relativamente fácil de instalar
- En comparación con las listas de permitir/denegar, analiza señales más avanzadas que solo la identidad
- Protección probada contra ataques como DDoS y bots de scraping básicos
- Más automatizado que los controles manuales del servidor
Limitaciones
- Puede ser eludido por agentes de IA fraudulentos que imitan el comportamiento humano
- Tiene dificultades para detectar agentes de navegador alojados localmente, que son cada vez más adoptados por consumidores y atacantes
- Se basan en señales a nivel de aplicación, con señales de nivel de interacción muy básicas
- Sin capacidad para guiar a los agentes de IA de consumidor en el proceso de compra
- Visibilidad débil en las señales del lado del cliente
Las herramientas de detección de bots heredadas no están preparadas para los agentes de IA: Estas soluciones se construyeron para una era en la que los bots vivían en infraestructura cloud, no podían razonar y seguían patrones predecibles. Los agentes de IA modernos se ejecutan dentro de navegadores reales y se mezclan con el tráfico normal. El bloqueo indiscriminado detendrá el abuso evidente, pero una estrategia moderna de gobernanza de agentes requiere comprender la intención y establecer reglas dinámicas.
Nuestras pruebas internas en cside lograron eludir la detección de bots tradicional en 80 de 100 intentos con un esfuerzo mínimo.
4. Herramientas especializadas de detección de agentes de IA (p. ej., cside)
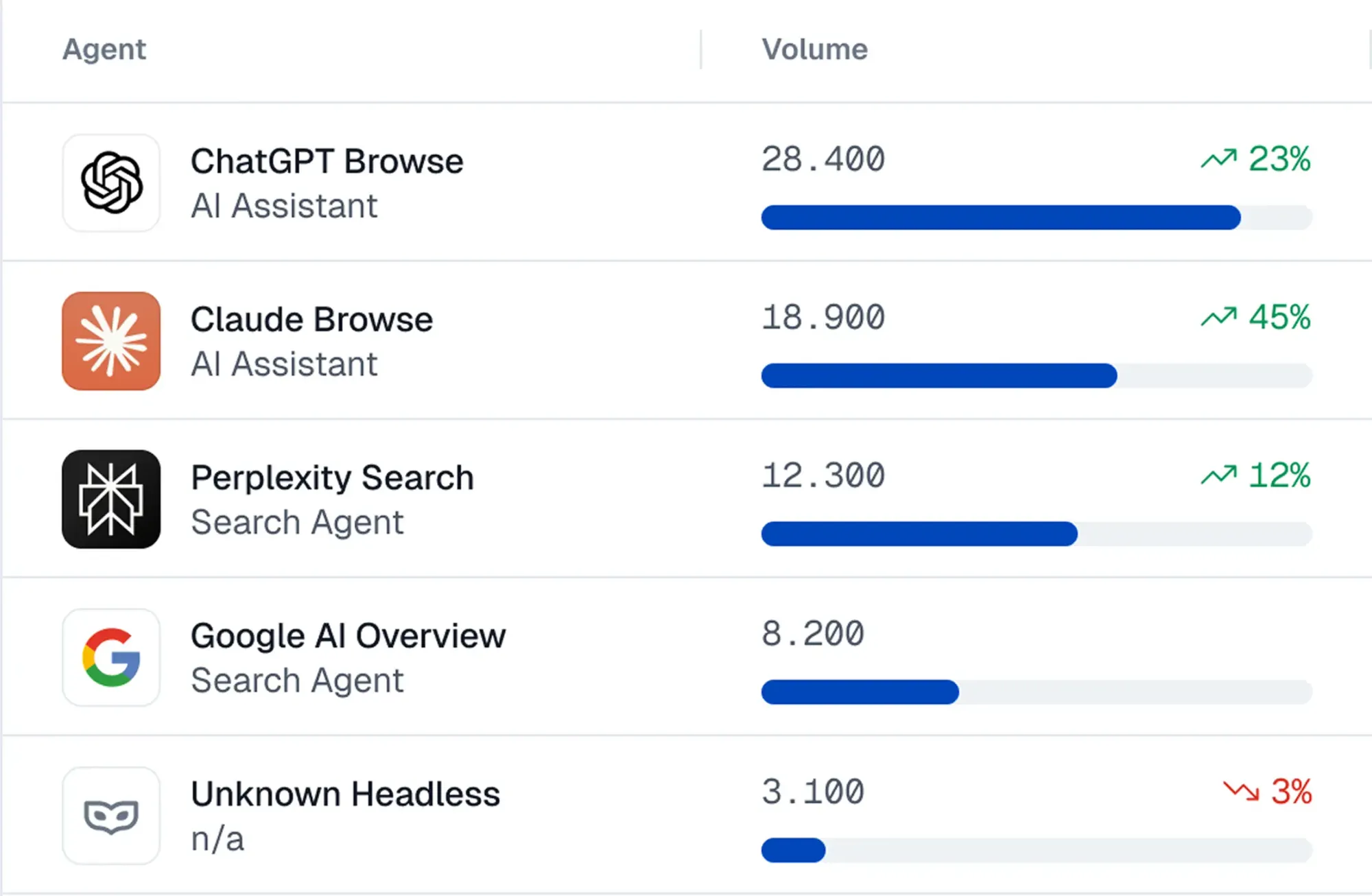
Cómo funciona: Se instala un fragmento de código en tu sitio, lo que te da control sobre:
- Detección: Observa docenas de señales para identificar agentes de IA, sus acciones y el riesgo de fraude.
- Bloqueo: Se crean puntuaciones de riesgo a partir de una variedad de señales: patrones de interacción, huellas digitales, contexto de ejecución de JavaScript, bases de datos de reputación, honeypots y más. Puedes revisar el riesgo de los agentes y establecer reglas dinámicas para bloquearlos por completo o permitirles acceso limitado.
- Gobernanza: Los desarrolladores utilizan un SDK para añadir salvaguardas a las sesiones de agentes. Por ejemplo, ciertos pasos pueden requerir validación humana, o se puede permitir que determinados agentes de confianza realicen compras mientras otros quedan restringidos al modo de solo lectura.
Ventajas
- Fácil de desplegar con paneles de control para equipos de fraude y SDKs para desarrolladores
- Diseñado específicamente para agentes de IA. cside es mejor para detectar agentes de IA de navegador alojados localmente (p. ej., Playwright, Selenium)
- Más eficaz para detectar agentes que operan desde extensiones de navegador (Manus AI, Comet)
- Diseñado para prevenir ataques y fraudes basados en agentes, no solo para "bloquear rastreadores"
- Capacidades de gobernanza para mejorar las experiencias de comercio agéntico
- Visibilidad sobre el tráfico agéntico. Un panel de control con qué agentes están en tu sitio, qué acciones están realizando, dónde se quedan bloqueados y qué riesgo representan.
Las pilas modernas de seguridad web necesitan una herramienta especializada de detección de agentes de IA: Bloquear "bots" y rastreadores ya no es suficiente. Los agentes de IA requieren clasificación del comportamiento y reglas dinámicas. Herramientas como cside AI Agent detection dan a las empresas esta visibilidad para que el fraude pueda bloquearse sin afectar a los agentes de consumidor legítimos.
Por qué deberías bloquear (algunos) agentes de IA de tu sitio web

No todos los agentes de IA son dañinos. Algunos asisten a los consumidores. Otros actúan como herramientas de investigación. Pero muchos agentes son fraudulentos. Un informe de investigación de Ahrefs encontró que el 63% de los sitios web reciben tráfico agéntico. Eso fue a principios de 2025. A estas alturas, ese porcentaje probablemente sea mayor.
Por qué bloquear rastreadores y scrapers:
La conversación sobre el tráfico agéntico se centra actualmente en los rastreadores visibles de ChatGPT, Gemini u otras plataformas LLM que obtienen contenido para respuestas o para entrenar modelos. La motivación para bloquear rastreadores y scrapers es válida, especialmente para empresas con contenido único, como editores o servicios de streaming de medios que se enfrentan a:
- Scraping de contenido premium para piratería
- Recopilación de contenido para entrenar modelos LLM sin permiso
Por qué los agentes de IA fraudulentos:
Los rastreadores de plataformas LLM no son la única amenaza. De hecho, están en el lado "más seguro" del espectro de automatización de bots. La amenaza más preocupante es cómo el abuso automatizado de los atacantes se verá amplificado por los agentes de IA. Los agentes facilitan eludir la detección e imitar el comportamiento humano.
Un informe sobre delitos financieros del Departamento del Tesoro de EE. UU. señala cómo los agentes de IA reducen la barrera para técnicas de ataque sofisticadas que anteriormente requerían muchos recursos, y hacen que el fraude automatizado sea accesible para atacantes con poca experiencia.
Amenazas agénticas para los equipos de seguridad:
- Intentos automatizados de toma de control de cuentas
- Descubrimiento de vulnerabilidades asistido por IA
- Abuso de flujos de usuarios autenticados
- Manipulación del proceso de pago mediante scripts
Amenazas agénticas para los equipos de fraude:
- Prueba de credenciales robadas a escala
- Abuso de códigos promocionales y cupones
- Automatización de flujos de fraude en devoluciones
- Perfiles falsos creados con documentos de identidad e imágenes generadas por LLMs
Amenazas agénticas para los equipos de eCommerce:
- Acaparamiento de inventario por compradores automatizados
- Scraping de precios
- Fraude de enlaces de afiliados
Cómo bloquear agentes de IA en tu sitio web (paso a paso)
Paso 1: Identifica los agentes de IA en tu sitio web (quiénes son)
Con una herramienta de detección:
- Para obtener un panel de control instantáneo de agentes de IA fraudulentos y tráfico de rastreadores, puedes usar cside Agent Detection.
- Si tu sitio web está conectado a Cloudflare, puedes consultar su panel de Bot Analytics para obtener un desglose del tráfico de rastreadores de IA.
- Para visibilidad específica de SEO sobre el tráfico de rastreadores de IA, puedes usar el analizador de registros de Screaming Frog. Esta herramienta analizará tus registros de servidor sin procesar y visualizará un informe de tráfico.
Por tu cuenta:
Si un rastreador de IA se identifica públicamente, mostrará señales identificables en la capa de solicitud. Comprueba las cadenas de user-agent que existen en las solicitudes HTTP. Para acceder a esta información tendrás que ir a los registros de tu servidor y buscar campos que se correlacionen con identidades de agentes de IA:
- GPTBot
- ChatGPT-User
- ClaudeBot
Paso 2: Comprende qué acciones realizan los agentes de IA en tu sitio (qué están haciendo)
Con una herramienta de detección especializada: Las plataformas de gobernanza de agentes de IA como cside AI Agent Detection o HUMAN Agentic Trust monitorizan la ejecución del navegador, los flujos de navegación y los patrones de comportamiento. Esto desplaza el análisis de "¿es esto un bot?" a "¿qué intenta conseguir este bot?". Una capa de detección moderna verá:
- Si un agente está activando flujos de inicio de sesión o de pago
- Intentos repetidos contra endpoints sensibles
- Envíos automatizados de formularios
Por tu cuenta: Descubrir manualmente qué hacen los agentes de IA requiere analizar registros del servidor, tiempos de solicitud y patrones de ejecución de JavaScript.
Paso 3: Comprende la intención detrás de los agentes de IA (¿representan un riesgo?)
Comprender la intención de los agentes de IA requiere distinguir entre la automatización que es útil y la que es dañina. Las herramientas de detección de bots tradicionales no fueron diseñadas para manejar agentes que imitan el comportamiento humano y se ejecutan desde dentro del entorno de navegador de un usuario auténtico.
Con una herramienta de detección especializada: Soluciones como cside AI Agent Detection o la plataforma Agent Trust de DataDome fueron diseñadas para la internet agéntica. Te ayudan a distinguir entre agentes de IA de consumidor que asisten con investigación y compras, frente a agentes de IA fraudulentos que abusan de códigos promocionales, extraen información o crean perfiles falsos.
En lugar de tomar decisiones binarias sobre la identidad, estas plataformas utilizan reglas avanzadas de puntuación de riesgo creadas por ingenieros de seguridad. Estas analizan señales como:
- Solicitudes excesivas o anómalas
- Uso de VPNs o proxies
- Entornos de ejecución de navegador sospechosos
- Fingerprinting para detectar la reutilización de dispositivos en flujos de riesgo (como el canje de códigos promocionales)
- Interacciones y análisis de comportamiento
Paso 4: Gobierna los agentes de IA según su comportamiento (bloquear, confiar o guiar)
Una vez que comprendes qué hacen los agentes de IA en tu sitio, puedes decidir cómo permitirles interactuar con tu sitio web. La reacción instintiva es bloquear todo excepto los rastreadores que ayudan con el SEO o la búsqueda de IA. Ese enfoque es bueno para la seguridad, pero excluye a los agentes de IA legítimos que podrían estar investigando productos, reservando entradas, rellenando formularios o enviando consultas.
Por eso la detección de bots tradicional se queda corta en la era agéntica. Te ofrecen lógica básica de permitir/denegar. La era agéntica requiere más matices. Los "bots" agénticos serán creados por consumidores a diario, omnipresentes en la navegación por internet. Una estrategia madura de gobernanza agéntica determina "¿qué debería poder hacer esta sesión agéntica?".
Por ejemplo:
- Los agentes de investigación pueden requerir solo acceso de solo lectura a tu sitio web
- Los agentes basados en tareas pueden tener permiso para enviar formularios o solicitar información
- Esos mismos agentes basados en tareas pueden ver revocado su permiso para acciones en páginas sensibles como portales de gestión de perfiles
Plataformas como cside AI Agent Detection admiten este tipo de gobernanza basada en el comportamiento. Los paneles de control facilitan a los equipos de fraude obtener datos para detener el abuso de agentes de IA de forma temprana. Los desarrolladores obtienen un SDK y bibliotecas para personalizar la experiencia para agentes basados en navegador, impulsando aún más el comercio agéntico.
Por qué robots.txt no es suficiente para bloquear agentes de IA
robots.txt es una directiva voluntaria, no un control de seguridad. Solicita a los rastreadores especificados que no accedan a tu sitio, pero no les impide técnicamente hacerlo. robots.txt puede ser un mecanismo útil para bloquear los principales rastreadores (Meta, ChatGPT, GoogleBot) que se comprometen a respetar esta directiva, pero no hace mucho para detener el fraude de agentes de IA.
Los asistentes de IA y los rastreadores de búsqueda no siempre cumplen con robots.txt
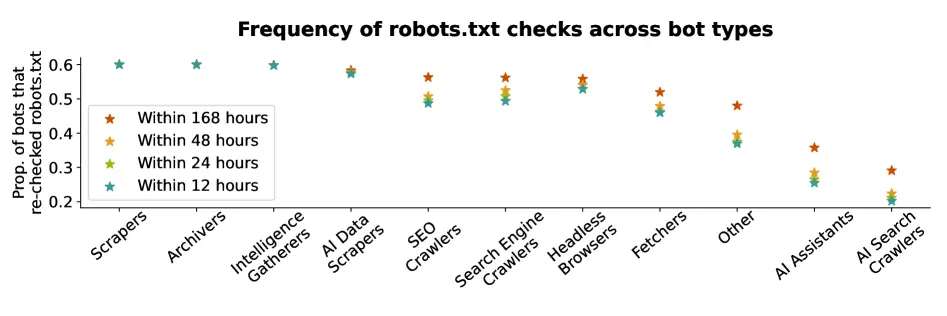
Un informe de investigación académica de 2025 de la Universidad de Duke muestra que solo aproximadamente el 60% de los asistentes de IA y rastreadores de búsqueda de IA consultarán o cumplirán con las solicitudes 'disallow' de robots.txt. Ese promedio probablemente esté sesgado al alza por los bots de ChatGPT y GoogleBot, que respetan la directiva más del 99% de las veces.
Algunos bots populares como Perplexity solo respetan la directiva 'disallow' aproximadamente el 20% de las veces.
Los agentes de IA que usan navegadores headless (como los agentes personalizados creados por consumidores) respetan robots.txt en menor medida, cumpliendo con las directivas 'disallow' aproximadamente el 10% de las veces.
Suplantación de user-agent para eludir robots.txt
robots.txt se basa en cadenas de "user-agent" autodeclaradas. Es como que te pregunten cuál es tu nombre. Puedes autodeclarar que es cualquier cosa que quieras. Si intentas entrar a un evento y sabes que el nombre "Brad Pitt" está en la lista, puedes decir que ese es tu nombre. En el mundo real puede que te pidan que muestres alguna prueba. En cambio, robots.txt no tiene forma de confirmar que las identidades son realmente válidas.
Así que los agentes fraudulentos pueden declarar ser "Claudebot" o "GPTBot". Si esas identidades están permitidas en tu sitio, robots.txt los dejará pasar sin problema.
La detección de bots tradicional (como Cloudflare) no detecta los agentes de IA
Los sistemas de detección de bots tradicionales fueron diseñados para una era en la que la automatización se ejecutaba desde servidores en la nube o redes de proxies evidentes. Estos sistemas dependen en gran medida de las señales de la capa de red y de las bases de datos de reputación, con visibilidad limitada sobre la ejecución de JavaScript y las interacciones con el sitio web.
El auge de la automatización basada en navegador alojada localmente
Una clase creciente de automatización ahora se ejecuta dentro de entornos de navegador reales:
- Agentes de consumidor que se ejecutan en extensiones de navegador como Manus o la extensión de navegador de Claude
- Automatizaciones creadas por desarrolladores que utilizan herramientas de navegador headless como Playwright o Selenium que se ejecutan en máquinas o incluso dispositivos móviles
- Actores fraudulentos que utilizan herramientas de navegador headless de código abierto para llevar a cabo ataques
Esta categoría de agentes surgió en parte para facilitar a los consumidores y desarrolladores legítimos el despliegue de bots de IA que interactúan con la web. También surgió como un esfuerzo intencional para evitar la detección de las herramientas de gobernanza de bots heredadas.
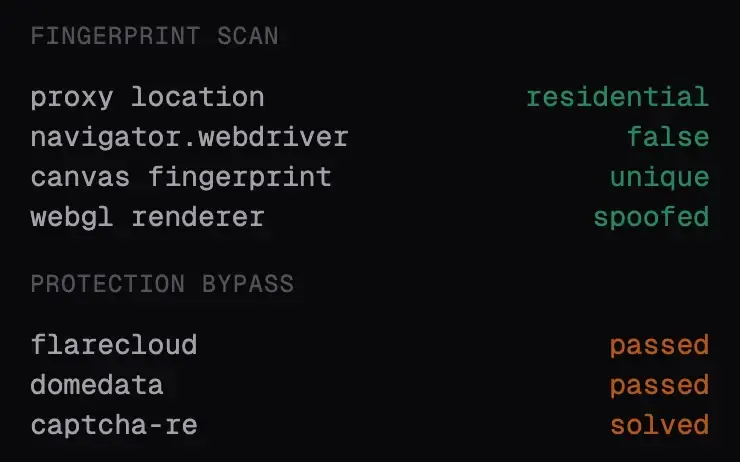
Estos agentes basados en navegadores headless no se identifican claramente. De hecho, intentan intencionalmente parecer un usuario humano real, lo que dificulta la detección del fraude (y contamina los análisis en el proceso).
Detectar agentes basados en navegadores headless requiere una herramienta especializada de detección de agentes de IA que analice señales de comportamiento y contexto profundo del navegador.
Cómo cside ayuda a las empresas a bloquear a los atacantes agénticos
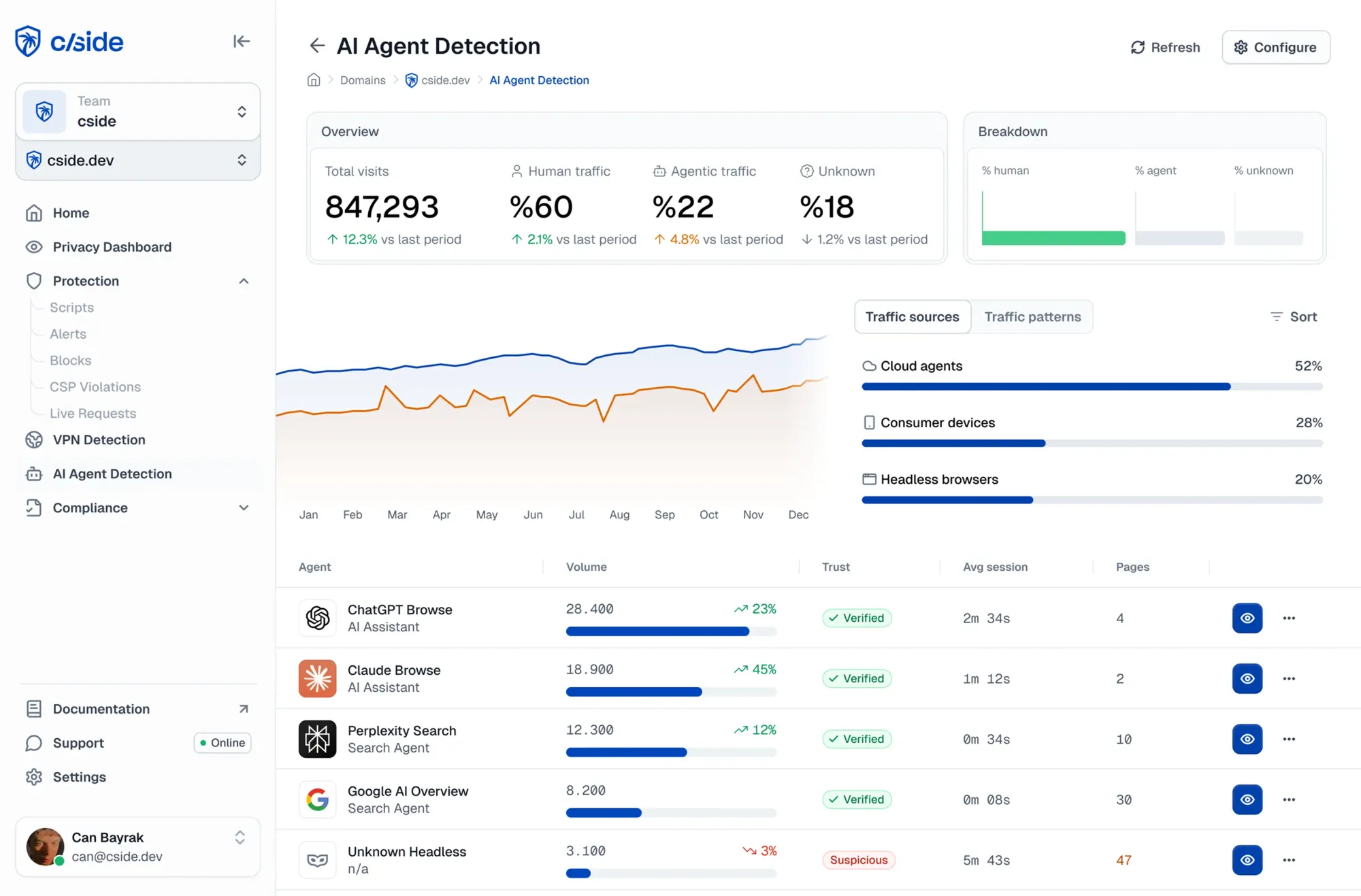
cside es una plataforma de seguridad web especializada en la monitorización de señales de la capa del navegador para reducir el fraude en empresas. cside AI Agent Detection te ayuda a identificar, clasificar y gobernar el tráfico agéntico en tu sitio web.
- Obtén un panel de control con qué agentes acceden a tu sitio y qué están haciendo
- Puntuaciones de riesgo automáticas a partir de señales de comportamiento para detectar agentes de IA maliciosos (incluidos los basados en navegador y los alojados localmente) que eluden las defensas tradicionales contra bots
- Proporciona a tus desarrolladores herramientas para establecer salvaguardas sobre lo que pueden hacer los agentes
- Previene el fraude de agentes de IA como el abuso de códigos promocionales, la piratería de contenido, la prueba de tarjetas de crédito, el descubrimiento de vulnerabilidades y el scraping avanzado.
Puedes empezar a ver el tráfico agéntico en tu sitio web con una cuenta gratuita.








