

On-device AI inference is moving into operating systems, browsers, and productivity tools. That shift changes the security model. Sensitive data can stay closer to the user, but the model also gets closer to files, browser state, clipboard contents, and local system tools.
Two May 2026 stories show why this matters now. Security researcher Alexander Hanff reported that Google Chrome was downloading a roughly 4GB Gemini Nano model to devices without a clear consent prompt. Around the same period, Claude Desktop browser integrations drew scrutiny because local browser bridges can expand what an AI assistant can reach.
The lesson is not that on-device inference is bad. The lesson is that powerful local models need the same security discipline as any privileged local process: explicit permissions, strict input boundaries, auditable telemetry, and browser-layer visibility.
What omnivore inference changes
"Omnivore inference" is a useful phrase for this problem. Local models become valuable because they can consume more context: files, clipboard data, browser history, visible page content, running processes, and device state.
That context makes the assistant useful. It also makes the assistant a high-value target.
When a local model runs with broad permissions, an attacker no longer needs to steal the data source directly. They can try to steer the model into reading, summarizing, transforming, or sending the data for them.
The browser is the obvious entry point
The browser is where many untrusted inputs meet privileged local tooling. A malicious page, compromised browser extension, or third-party script loaded through a supply-chain attack can all become model input.
If a local LLM exposes a local endpoint or browser bridge without strong authorization, arbitrary client-side JavaScript becomes a risk. A script could attempt to query the model, ask it to summarize sensitive local context, or push it toward a tool call the user never intended.
This is why client-side security is part of the local AI security story. Security teams need to know which scripts execute in the browser, what they load, and whether they attempt behavior outside their expected role.
Why prompt injection has a bigger blast radius locally
Prompt injection is the top-ranked risk in the OWASP Top 10 for LLM Applications. In a cloud chatbot, a successful injection can manipulate output, leak accessible context, or bypass policy controls.
On a local model, the impact can be broader. If the model has filesystem access, browser access, command execution, or network tools, the attack shifts from "what can the model say?" to "what can the model do?"
Tool access turns the model into an operator
Tool access is the line that matters. Reading a file, sending an HTTP request, clicking in a browser, or executing a command turns the model from a text generator into an operator.
An injected instruction does not need to exploit the operating system directly. It only needs to reach a trusted model interface that already has permission to act.
Anthropic's own Mythos Preview materials show the defensive promise and the risk. Project Glasswing is built around using Mythos-class reasoning to find and fix serious vulnerabilities. At the same time, Anthropic has noted that stronger vulnerability patching capability also implies stronger exploitation capability. Reporting on Mythos testing described autonomous exploit chaining under controlled conditions, including browser and sandbox escape work.
That does not mean every local model is an exploit platform. It means permission boundaries matter more as model capability increases.

How local LLM telemetry can still leak sensitive data
On-device inference is often framed as a privacy win. The raw prompt, file, or document does not need to travel to a cloud model endpoint. For healthcare, legal, finance, and enterprise engineering teams, that is a real benefit.
But local does not mean silent.
Telemetry, diagnostic logs, model performance metrics, update checks, crash reports, and integration metadata can still leave the device. These flows are often treated as operational data, not sensitive data.
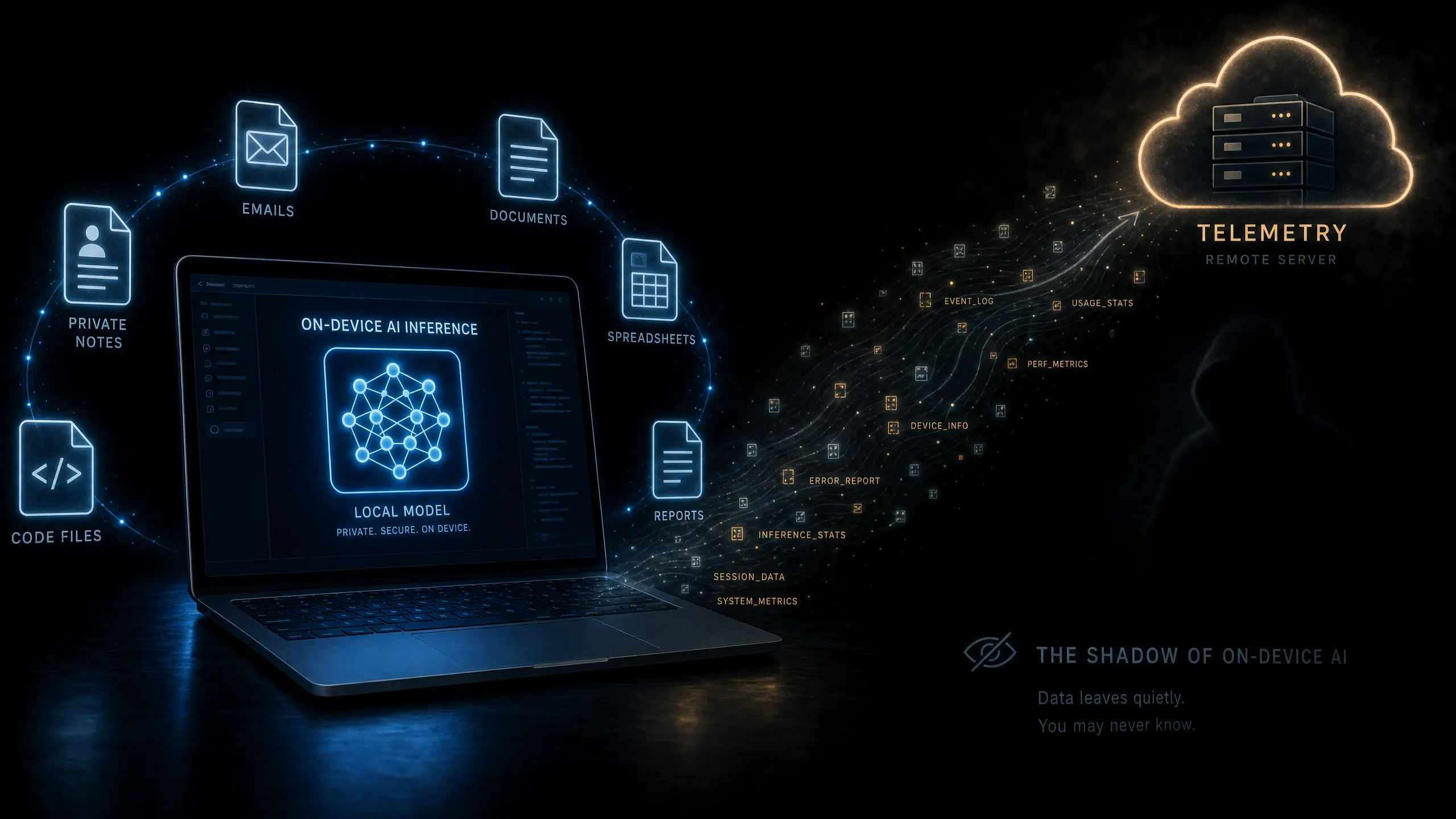
The shadow of local inference
A model that reads private documents or code repositories can produce sensitive traces even when raw prompts stay local. Error messages can contain snippets. Usage patterns can reveal activity. Diagnostic payloads can include file names, extension state, prompt categories, or model routing data.
Local inference tools have already faced scrutiny for usage telemetry and privacy defaults. For regulated teams, telemetry needs classification, retention controls, and an audit path. It cannot be treated as harmless exhaust.
The privacy upside is still real
On-device inference solves a genuine problem. Sensitive data does not need to be sent to a third-party inference API for every task. That reduces exposure to cloud retention policies, provider-side compromise, API credential theft, and interception of model traffic.
For security products, this creates a powerful design option. A local model can inspect code, scripts, browser activity, and endpoint behavior without shipping every artifact to a vendor.
The privacy model is strong when the implementation is disciplined. It breaks down when downloads are silent, integrations install without clear user intent, telemetry scope is vague, or local endpoints are reachable by untrusted browser content.
What LLM-powered endpoint security can do
On-device inference also opens a defensive path that traditional endpoint tools struggle to match. Signature systems detect known patterns. Heuristics flag suspicious features. Both can miss novel, obfuscated, or multi-stage attacks.
A local model that understands code can reason about intent. It can inspect a script and ask what the script is trying to accomplish, not only whether it matches a known indicator.
| Capability | Traditional AV/EDR | LLM-powered endpoint security |
|---|---|---|
| Novel malware detection | Signature-dependent | Semantic code understanding |
| Obfuscated script analysis | Limited heuristics | Intent-level reasoning |
| Multi-stage attack chains | Per-event analysis | Sequence-level analysis |
| Zero-day discovery | Mostly reactive | Proactive reasoning about behavior |
| False positive handling | Rule tuning | Context-aware triage |
This is the good version of the same architecture. A local security model can inspect browser extensions before they execute, analyze third-party scripts during runtime, and flag behavior that looks like credential harvesting or data exfiltration.
The difference between a defensive agent and an extraction tool is the trust boundary around inputs, tools, and outputs.
Controls security teams should require
On-device inference needs a security model before it becomes background infrastructure.
- Explicit permissions. Local models should not get default access to files, clipboard data, browser content, or process state. Permissions should be visible, granular, and revocable.
- Strong model interface controls. Treat every model input as potentially adversarial. Prompt injection defenses belong at the interface and tool layer, not only inside the model prompt.
- Telemetry limits. Keep telemetry minimal, documented, and auditable. Do not allow diagnostic payloads to carry user data, file contents, or sensitive local context.
- Network isolation. Local model endpoints should not be reachable from arbitrary browser requests. The local endpoint is not a public API.
- Browser script visibility. Monitor the third-party scripts, extensions, and injected content that can interact with local AI tooling. If you cannot trust the browser runtime, you cannot safely expose privileged local models to it.
How cside fits
cside monitors the browser runtime: the scripts that load, the code that executes, the domains they contact, and the behavior that changes after deployment. That matters because the browser is one of the most likely places where local AI tooling will meet untrusted input.
For teams deploying or evaluating on-device AI, cside client-side security helps answer the operational question: what is actually happening in the browser before it reaches a privileged local model, checkout flow, login form, or sensitive user session?
On-device inference will improve security tools. It will also create new attack paths. The outcome depends on whether teams build permission boundaries and runtime visibility before local models become another invisible dependency.







