

La inferencia de IA en el dispositivo se está integrando en sistemas operativos, navegadores y herramientas de productividad. Ese cambio modifica el modelo de seguridad. Los datos sensibles pueden quedarse más cerca del usuario, pero el modelo también queda más cerca de archivos, estado del navegador, contenido del portapapeles y herramientas locales del sistema.
Dos historias de mayo de 2026 muestran por qué esto importa ahora. El investigador de seguridad Alexander Hanff reportó que Google Chrome descargaba un modelo Gemini Nano de unos 4GB en dispositivos sin un aviso claro de consentimiento. En el mismo periodo, las integraciones de navegador de Claude Desktop recibieron críticas porque los puentes locales del navegador pueden ampliar lo que un asistente de IA puede alcanzar.
La lección no es que la inferencia en el dispositivo sea mala. La lección es que los modelos locales potentes necesitan la misma disciplina de seguridad que cualquier proceso local privilegiado: permisos explícitos, límites estrictos de entrada, telemetría auditable y visibilidad en la capa del navegador.
Qué cambia con la inferencia omnívora
"Inferencia omnívora" es una frase útil para este problema. Los modelos locales se vuelven valiosos porque pueden consumir más contexto: archivos, datos del portapapeles, historial del navegador, contenido visible de páginas, procesos en ejecución y estado del dispositivo.
Ese contexto hace útil al asistente. También convierte al asistente en un objetivo de alto valor.
Cuando un modelo local se ejecuta con permisos amplios, un atacante ya no necesita robar directamente la fuente de datos. Puede intentar guiar al modelo para que lea, resuma, transforme o envíe esos datos por él.
El navegador es el punto de entrada obvio
El navegador es donde muchas entradas no confiables se encuentran con herramientas locales privilegiadas. Una página maliciosa, una extensión comprometida o un script de tercero cargado por un ataque de cadena de suministro pueden convertirse en entrada para el modelo.
Si un LLM local expone un endpoint local o un puente de navegador sin autorización sólida, cualquier JavaScript del lado del cliente se vuelve un riesgo. Un script podría intentar consultar el modelo, pedirle que resuma contexto local sensible o empujarlo hacia una llamada de herramienta que el usuario nunca quiso ejecutar.
Por eso la seguridad del lado del cliente forma parte de la historia de seguridad de la IA local. Los equipos de seguridad necesitan saber qué scripts se ejecutan en el navegador, qué cargan y si intentan comportamientos fuera de su función esperada.
Por qué la inyección de prompts tiene más impacto en local
La inyección de prompts es el principal riesgo en el OWASP Top 10 para aplicaciones LLM. En un chatbot en la nube, una inyección exitosa puede manipular la salida, filtrar contexto accesible o evadir controles de política.
En un modelo local, el impacto puede ser mayor. Si el modelo tiene acceso al sistema de archivos, al navegador, a ejecución de comandos o a herramientas de red, el ataque cambia de "¿qué puede decir el modelo?" a "¿qué puede hacer el modelo?".
El acceso a herramientas convierte al modelo en operador
El acceso a herramientas es la línea importante. Leer un archivo, enviar una solicitud HTTP, hacer clic en un navegador o ejecutar un comando convierte al modelo de generador de texto en operador.
Una instrucción inyectada no necesita explotar directamente el sistema operativo. Solo necesita alcanzar una interfaz de modelo confiable que ya tiene permiso para actuar.
Los materiales de Mythos Preview de Anthropic muestran tanto la promesa defensiva como el riesgo. Project Glasswing se basa en usar razonamiento de clase Mythos para encontrar y corregir vulnerabilidades graves. Al mismo tiempo, Anthropic ha señalado que una mayor capacidad para parchear vulnerabilidades también implica una mayor capacidad para explotarlas. La cobertura sobre pruebas de Mythos describió encadenamiento autónomo de exploits en condiciones controladas, incluido trabajo de escape de navegador y sandbox.
Eso no significa que cada modelo local sea una plataforma de exploits. Significa que los límites de permisos importan más a medida que aumenta la capacidad del modelo.

Cómo la telemetría de LLM locales aún puede filtrar datos sensibles
La inferencia en el dispositivo suele presentarse como una ventaja de privacidad. El prompt, archivo o documento sin procesar no tiene que viajar a un endpoint de modelo en la nube. Para equipos de salud, legal, finanzas e ingeniería empresarial, eso es un beneficio real.
Pero local no significa silencioso.
La telemetría, los logs de diagnóstico, las métricas de rendimiento del modelo, las comprobaciones de actualización, los informes de fallos y los metadatos de integración pueden seguir saliendo del dispositivo. Estos flujos suelen tratarse como datos operativos, no como datos sensibles.
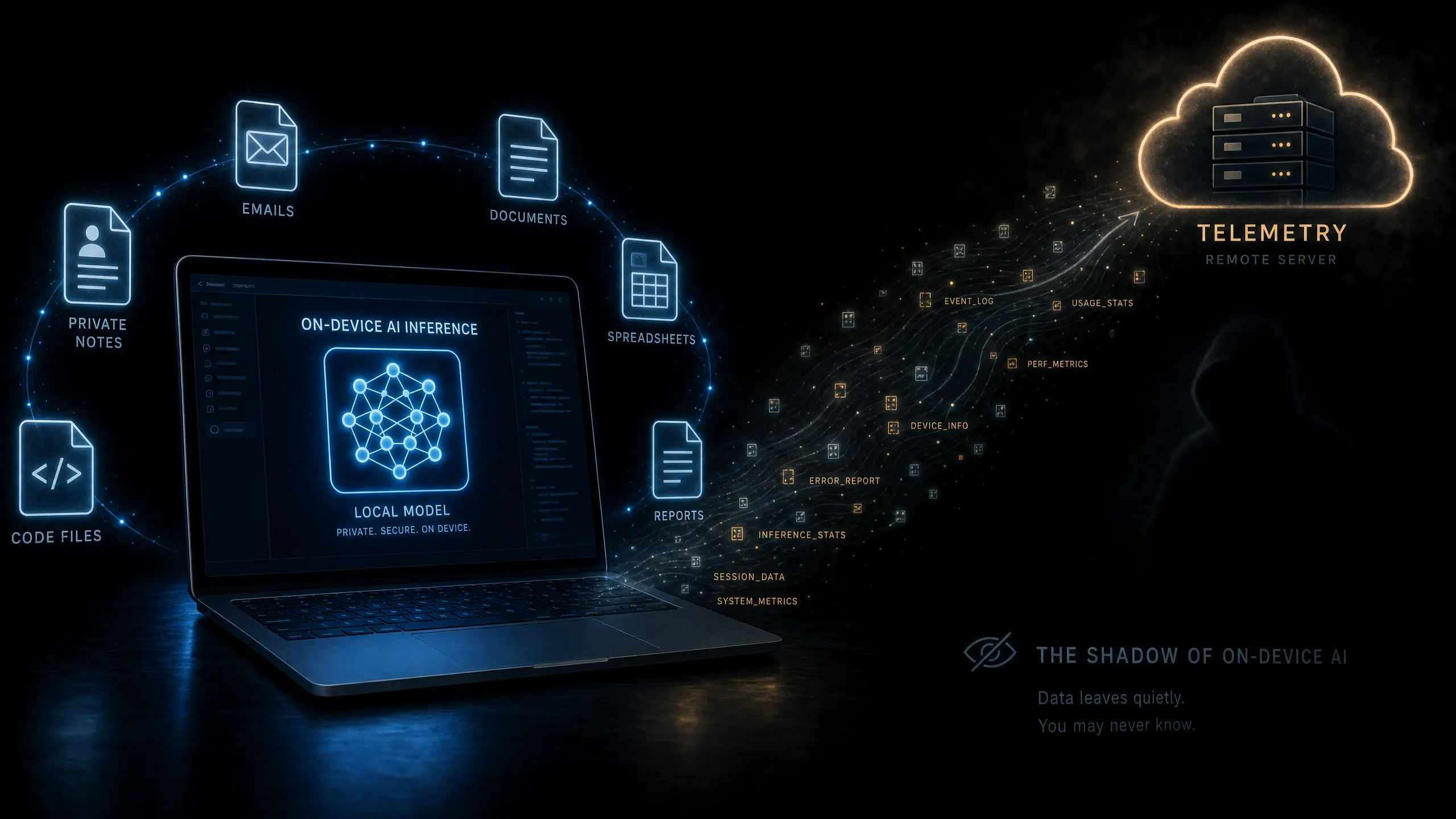
La sombra de la inferencia local
Un modelo que lee documentos privados o repositorios de código puede producir rastros sensibles incluso cuando los prompts sin procesar se quedan en local. Los mensajes de error pueden contener fragmentos. Los patrones de uso pueden revelar actividad. Las cargas de diagnóstico pueden incluir nombres de archivo, estado de extensiones, categorías de prompts o datos de enrutamiento del modelo.
Las herramientas de inferencia local ya han recibido escrutinio por telemetría de uso y valores predeterminados de privacidad. Para equipos regulados, la telemetría necesita clasificación, controles de retención y una ruta de auditoría. No puede tratarse como ruido inocuo.
La ventaja de privacidad sigue siendo real
La inferencia en el dispositivo resuelve un problema genuino. Los datos sensibles no tienen que enviarse a una API de inferencia de terceros para cada tarea. Eso reduce la exposición a políticas de retención en la nube, compromisos del proveedor, robo de credenciales de API e interceptación de tráfico del modelo.
Para productos de seguridad, esto crea una opción potente de diseño. Un modelo local puede inspeccionar código, scripts, actividad del navegador y comportamiento endpoint sin enviar cada artefacto a un proveedor.
El modelo de privacidad es fuerte cuando la implementación es disciplinada. Se rompe cuando las descargas son silenciosas, las integraciones se instalan sin intención clara del usuario, el alcance de la telemetría es vago o los endpoints locales son accesibles desde contenido de navegador no confiable.
Qué puede hacer la seguridad endpoint con LLM
La inferencia en el dispositivo también abre una vía defensiva que las herramientas endpoint tradicionales tienen dificultades para igualar. Los sistemas de firmas detectan patrones conocidos. Las heurísticas marcan rasgos sospechosos. Ambos pueden fallar ante ataques nuevos, ofuscados o de varias etapas.
Un modelo local que entiende código puede razonar sobre la intención. Puede inspeccionar un script y preguntar qué intenta lograr, no solo si coincide con un indicador conocido.
| Capacidad | AV/EDR tradicional | Seguridad endpoint con LLM |
|---|---|---|
| Detección de malware nuevo | Depende de firmas | Comprensión semántica del código |
| Análisis de scripts ofuscados | Heurísticas limitadas | Razonamiento a nivel de intención |
| Cadenas de ataque de varias etapas | Análisis por evento | Análisis de secuencia |
| Descubrimiento de zero-days | Mayormente reactivo | Razonamiento proactivo sobre comportamiento |
| Gestión de falsos positivos | Ajuste de reglas | Triaje con contexto |
Esta es la buena versión de la misma arquitectura. Un modelo de seguridad local puede inspeccionar extensiones antes de que se ejecuten, analizar scripts de terceros durante el runtime y marcar comportamientos que parezcan robo de credenciales o exfiltración de datos.
La diferencia entre un agente defensivo y una herramienta de extracción está en el límite de confianza alrededor de entradas, herramientas y salidas.
Controles que los equipos de seguridad deberían exigir
La inferencia en el dispositivo necesita un modelo de seguridad antes de convertirse en infraestructura de fondo.
- Permisos explícitos. Los modelos locales no deberían tener acceso predeterminado a archivos, portapapeles, contenido del navegador o estado de procesos. Los permisos deben ser visibles, granulares y revocables.
- Controles fuertes en la interfaz del modelo. Trata cada entrada del modelo como potencialmente adversaria. Las defensas contra prompt injection pertenecen a la interfaz y la capa de herramientas, no solo al prompt del modelo.
- Límites de telemetría. Mantén la telemetría mínima, documentada y auditable. No permitas que los diagnósticos transporten datos de usuario, contenido de archivos o contexto local sensible.
- Aislamiento de red. Los endpoints locales del modelo no deberían ser accesibles desde solicitudes arbitrarias del navegador. El endpoint local no es una API pública.
- Visibilidad de scripts del navegador. Monitoriza scripts de terceros, extensiones y contenido inyectado que puedan interactuar con herramientas locales de IA. Si no puedes confiar en el runtime del navegador, no puedes exponer modelos locales privilegiados de forma segura.
Cómo encaja cside
cside monitoriza el runtime del navegador: los scripts que cargan, el código que se ejecuta, los dominios que contactan y el comportamiento que cambia después del despliegue. Esto importa porque el navegador es uno de los lugares más probables donde las herramientas de IA local se encontrarán con entradas no confiables.
Para equipos que despliegan o evalúan IA en el dispositivo, cside client-side security ayuda a responder la pregunta operativa: ¿qué ocurre realmente en el navegador antes de que llegue a un modelo local privilegiado, un checkout, un formulario de inicio de sesión o una sesión sensible?
La inferencia en el dispositivo mejorará las herramientas de seguridad. También creará nuevas rutas de ataque. El resultado dependerá de si los equipos construyen límites de permisos y visibilidad de runtime antes de que los modelos locales se conviertan en otra dependencia invisible.







