

TL;DR
- Het detecteren van AI-agent content scrapers vereist het kruislings verifiëren van vier signaallagen: identiteit, netwerk, browseromgeving en gedragssignalen.
- De meeste bedrijven gebruiken een AI-agentdetectietool zoals cside of Fingerprint om deze sessies te herkennen en handhavingsacties te onderbouwen.
- AI content scraping bots gebruiken AI-mogelijkheden (bijv. LLM-gestuurde extractie of browseragents) om website-inhoud te oogsten.
- Traditionele botdetectie vangt ze niet omdat deze scrapers vanaf residentiële IP's werken, JavaScript uitvoeren en CAPTCHA's oplossen.
Wat zijn AI-agent content scraping bots?

AI content scraping bots gebruiken AI-mogelijkheden (bijv. LLM-gestuurde extractie of browseragents) om website-inhoud te oogsten. Ze onderscheiden zich van traditionele scrapers: ze gebruiken echte browsers, passen zich aan wanneer pagina-indelingen veranderen en extraheren gestructureerde betekenis in plaats van alleen ruwe HTML.
Het AI-scraperspectrum
| Scrapertype | Identificeert zichzelf? | Volgt de regels? | Hoe aan te pakken |
|---|---|---|---|
| Trainingscrawlers (GPTBot, ClaudeBot, CCBot) | Ja | Meestal | Blokkeren of toestaan in robots.txt |
| Zoekbots (ChatGPT-User, PerplexityBot) | Ja | Ja | Toestaan als je AI-zoekzichtbaarheid wilt |
| Agressieve crawlers (Bytespider) | Soms | Soms | Blokkeren via robots.txt + IP-bereiken |
| Commerciële scrapingtools | Nee | Nee | Vereist gedragsdetectie |
| Autonome AI-agents | Nee | Nee | Vereist gedragsdetectie |
In 2026 bestaat het overgrote deel van AI-agentverkeer naar je website nog steeds uit crawlers van grote LLM-platforms (Claude, ChatGPT, Google). Dit is waar de meeste mensen aan denken bij "AI scrapers". Dit artikel behandelt deze, maar onze focus ligt op het moeilijkere probleem: doelgerichte scrapers die specifieke informatie van je website willen oogsten.
Kwaadaardige AI scrapers
- Concurrerende prijsbewaking die je productpagina's of offertestromen doorloopt om je prijsmodel te begrijpen. Ingezet door concurrenten of aggregatieplatforms.
- Content-piraterij en herpublicatie kopieert je originele content om elders door te verkopen of opnieuw te publiceren. Dit treft uitgevers, onderzoeksbureaus en elk bedrijf waar de content zelf het product is.
- Voorraad-arbitrage (bijv. ticket scalping) bots bewaken je voorraadniveaus en prijzen voor alles met beperkte beschikbaarheid en gebruiken die informatie om eerder te kopen dan echte klanten of het door te verkopen op tweedehandsmarkten. Gerund door scalpernetwerken en wederverkoopbedrijven.
- Leadgeneratie scrapers die contactgegevens of gebruikersprofielen van je platform halen en als leadlijsten verkopen. Bediend door databrokers en leadgeneratiebedrijven.
Scrapers van grote LLM-platforms
Er zijn hier twee typen: zoekbots (zoals ChatGPT-User en PerplexityBot) die je pagina's lezen zodat ze naar je kunnen verwijzen in AI-zoekresultaten, en trainingscrawlers (zoals GPTBot, ClaudeBot en Bytespider) die je content gebruiken om hun modellen te verbeteren.
Voor de meeste bedrijven is dit niet het urgente probleem. Je staat de zoekbots toe, blokkeert de trainers als dat zinvol is en gaat verder. We behandelen dit in onze gids over het blokkeren van AI-agentverkeer (inclusief waarom robots.txt alleen niet genoeg is).
Hoe detecteer je AI-agent content scraping bots
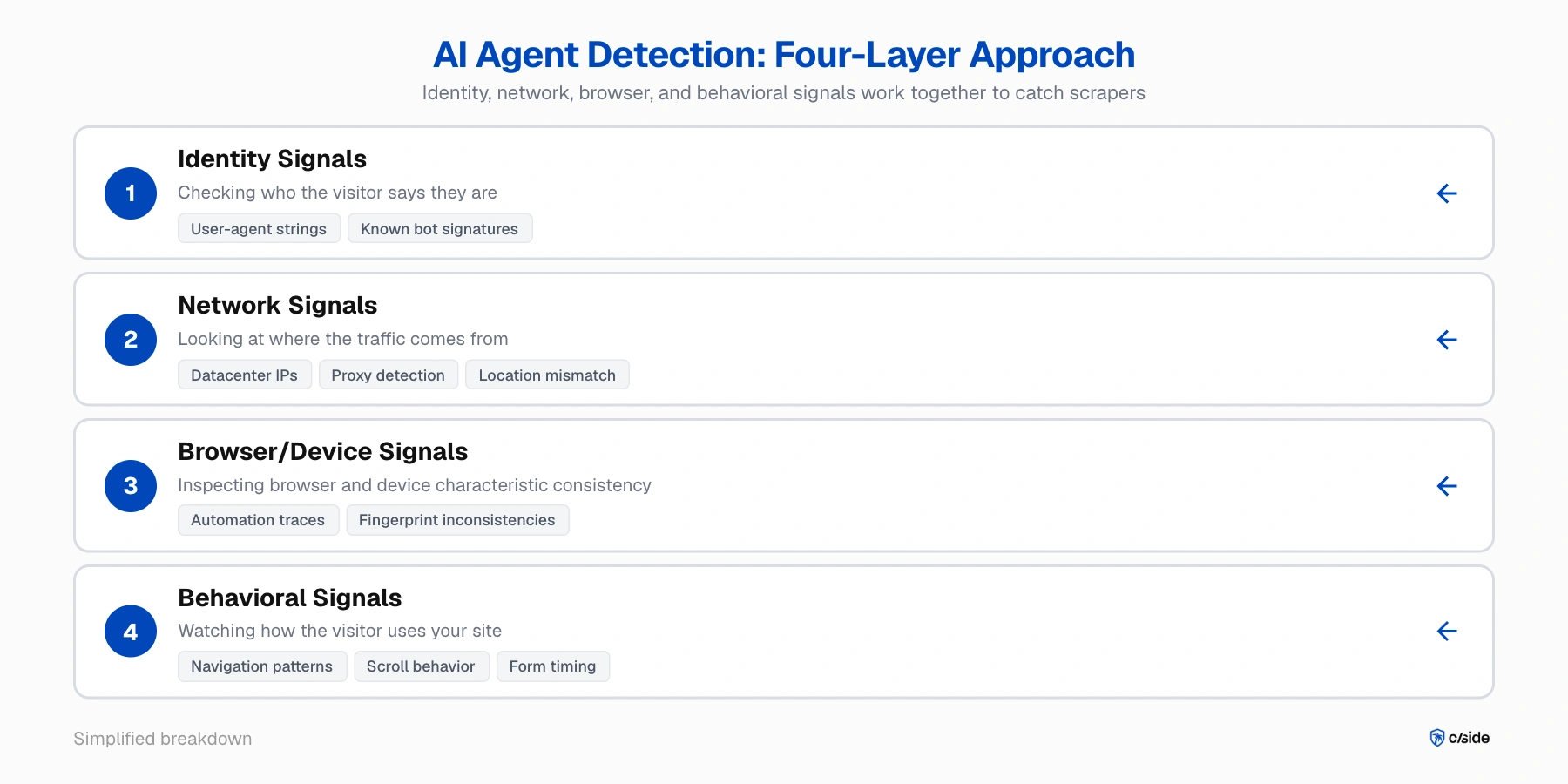
Een combinatie van netwerk-, browser- en gedragssignalen is nodig
Geen enkel signaal vangt een onopvallende scraper. De detectiemethodologie die we bij cside gebruiken (voor ons eigen platform en voor onze klanten) evalueert vier signaallagen samen:
- Identiteitssignalen; controleren wie de bezoeker zegt te zijn. Bekende crawlers zoals GPTBot kondigen zichzelf aan met user-agent strings. Andere geautomatiseerde bots, zoals die van Browserbase, hebben een botsignatuur die je kunt verifiëren.
- Netwerksignalen; kijken waar het verkeer vandaan komt. Is het een datacenter-IP? Een bekende proxy? Komt de opgegeven locatie overeen met de tijdzone van de browser? Dit vangt enkele eenvoudige opstellingen, maar geavanceerde operaties roteren residentiële IP's die er schoon uitzien.
- Browser-/apparaatsignalen; inspecteren of browser- en apparaatkenmerken consistent zijn. Automatiseringstools zoals Playwright laten sporen achter in de browserruntime. Wanneer fingerprintdetails (grafische rendering, audioverwerking, schermspecificaties) geen samenhangend verhaal vertellen, is er iets gemanipuleerd.
- Gedragssignalen; observeren hoe de bezoeker je site gebruikt. Navigatiepatronen, scrollgedrag, klikplaatsing, formulierinvultiming en verzoeksequenties op sessieniveau. AI-agent bots zijn veel beter in het maskeren hiervan dan traditionele bots, maar met gedetailleerde monitoring worden ze nog steeds betrapt.
Deze opsomming is beknopt gehouden. Als je een diepgaandere analyse wilt, hebben we een volledig artikel over het detecteren van AI-agentverkeer waarin we uitgebreider ingaan op specifieke signalen die cside-engineers in ons detectieplatform toepassen.
Gespecialiseerde vendortools om frauduleuze AI-agents te detecteren
Als je je zorgen maakt over AI-agent content scrapers en ze wilt stoppen, heb je fundamenteel twee keuzes. Kopen of zelf bouwen. Ons perspectief op het zelf bouwen van deze tooling is simpel: doe het niet. Botbeveiligingssoftware is een categorie die teams niet vaak zelf proberen te ontwikkelen (of te vibe-coden) om zeer logische redenen.
Het is een kat-en-muisspel. Je detectieaanpak zal reverse-engineered worden door de automatiseringsplatforms. Je team moet de detectiefilosofie continu bijwerken.
Een AI-agentdetectietool gericht op fraudedetectie is een veel eenvoudigere aanpak.
cside is een van die vendors, maar om onze educatieve artikelen objectief te houden noemen we regelmatig andere vendors (zoals HUMAN en Fingerprint).
Maar zijn vendortools niet extreem duur en bedoeld voor enterprises?
Veel ervan wel (DataDome, HUMAN), zoals we behandelden in onze vergelijkingsgids: 4 tools om AI-agents op je website te detecteren. Maar er zijn opties zoals cside en Fingerprint met voordeligere businessplannen (vanaf $99/maand) met de mogelijkheid om datasignalen naar je antifraude-workflows te sturen via een API. Dat betekent dat je alleen betaalt voor wat je gebruikt en flexibiliteit hebt over wat je met de detectiegegevens doet.
Zo betaal je niet de enterprise-prijs voor toeters en bellen die je niet nodig hebt. Je kunt ook de detectiemechanismen testen zonder vast te zitten aan een contract.
Wat AI scrapers op je website targeten
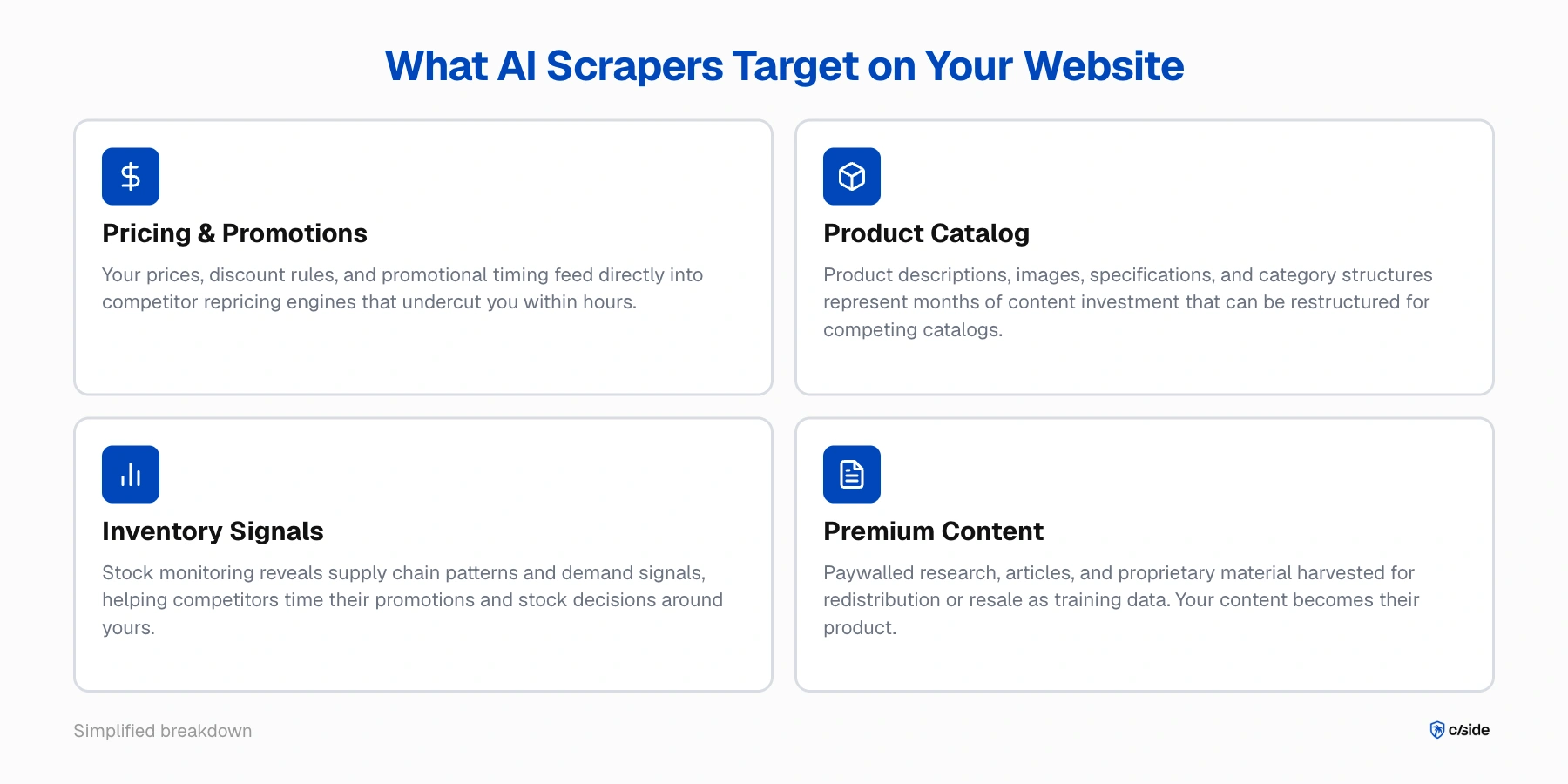
- Prijs- en promotiegegevens. Je prijzen, kortingsregels en promotietiming zijn real-time concurrerende inlichtingen. Een scraper die door je catalogus of offertestromen gaat, kan die data rechtstreeks naar een herprijzingsengine voeren die je binnen enkele uren onderbiedt.
- Productcatalogus en content. Je productbeschrijvingen, afbeeldingen, specificaties en categoriestructuren vertegenwoordigen maanden of jaren aan contentinvesteringen. AI scrapers kunnen alles opnemen en herstructureren voor een concurrerende catalogus.
- Voorraadsignalen. Herhaaldelijke monitoring van wat op voorraad is en wat niet, onthult je supply-chainpatronen en vraagsignalen. Die informatie is waardevol voor concurrenten die hun eigen promoties of voorraadbesluiten willen timen rond die van jou.
- Eigen onderzoek en premium content. Voor uitgevers, onderzoeksbureaus en contentbedrijven oogsten scrapers materiaal achter betaalmuren voor herdistributie of doorverkoop als trainingsdata. Je content wordt het product van iemand anders.
Voorbeeld: AI-agent content scraping bij een verzekeringsplatform
Hier is een voorbeeld uit de praktijk dat we met een van onze klanten hebben doorgewerkt:
- Een verzekeringsmaatschappij vermoedt dat iemand hun offertes scrapt. Sessies vullen steeds de volledige offerteflow in, krijgen de uiteindelijke prijs en vertrekken zonder te kopen. Ze hadden basisdetectie voor bots geïmplementeerd en die gaf aan dat er inderdaad verhoogde botactiviteit was, maar de meeste kwamen door zonder handhaving.
- Ze implementeren cside's AI-agentdetectie-API. Onmiddellijk werden bots die door andere verdedigingslagen glippen opgepikt. De signalen werden verbonden met de antifraude-workflows van het verzekeringsplatform. Een botrisicoclassificatieveld werd gebruikt om hun handhavingsbesluiten te onderbouwen.
- Wanneer een sessie wordt gemarkeerd als waarschijnlijk kwaadaardige AI-agent, toont de laatste stap een "neem contact op"-pagina in plaats van de daadwerkelijke offerte. De scraper krijgt niets bruikbaars. Maar als het toevallig een echt persoon is, kan die het proces alsnog afronden. Er lekken geen prijsgegevens naar concurrenten of aggregatieplatforms en er wordt geen echte klant afgewezen.
Aangezien het doel was "kwaadaardig prijsscraping stoppen" en niet alleen AI-agents detecteren, gebruikte dit verzekeringsplatform cside ook om aanmeldingen met wegwerp-e-mailadressen te herkennen.
Traditionele botdetectie faalt tegen AI-agent content scrapers
Traditionele botdetectie was gebouwd om verkeer met voorspelbare geautomatiseerde signalen te vangen: patroonmatige activiteit, verzoeken van datacenter-IP's zonder browseromgeving. Veel ervan konden worden gestopt met een simpele CAPTCHA. Wat AI-bots anders maakt:
- Lokaal gehoste automatisering. AI-scrapingagents draaien steeds vaker op echte consumentenhardware in plaats van cloudservers. Een Playwright-instantie op een Mac Mini verstuurt verzoeken vanaf een residentieel IP met authentieke apparaatfingerprints.
- Ze gebruiken echte browsers. Ze draaien in echte Chrome-instanties die je pagina's renderen, je JavaScript uitvoeren en zich precies zo gedragen als de browser van een klant.
- Ze zijn gebouwd om op mensen te lijken. AI-agents randomiseren hun timing, variëren hun scrollgedrag en lossen zelfs CAPTCHA's op.
De fraudekosten van content scraping
Content scraping is niet het soort aanval dat alarmen doet afgaan. Er is geen storing, geen losgeldbriefje, geen dramatisch incident. De schade is stiller: een concurrent die altijd binnen enkele uren je prijzen matcht, een namaakwinkel die producten verkoopt met exact jouw beschrijvingen, een aggregatieplatform dat je eigen data publiceert. Aberdeen Research schatte dat scraping e-commerce bedrijven tussen de 3% en 14% van de jaarlijkse website-omzet kost, en dat de mediane impact tot 80% van de algehele winstgevendheid van een site kan opeten.
Wat dit moeilijker te verteren maakt, is de asymmetrie. Een scrapingoperatie draaiende houden kost een paar honderd dollar per maand. De omzet die het bij het doelwit wegzuigt kan ordes van grootte hoger zijn. En de meeste organisaties kunnen niet eens kwantificeren hoeveel er wordt gescrapet, omdat ze het zicht missen om het te meten.
Handhavingsstrategieën voor AI-agent content scraping
Ga niet standaard alles blokkeren. Het instinct is om alles te blokkeren dat er geautomatiseerd uitziet, maar dat creëert twee problemen. Je tipt de scraper dat je detectie werkt, dus ze passen zich aan. En je riskeert het blokkeren van echte klanten, vooral tijdens piekperiodes wanneer het percentage valspositieven stijgt.
Serveer in plaats daarvan een bot-specifieke flow. De slimmere aanpak is om te wisselen wat de scraper ziet. Toon in plaats van een uiteindelijke prijs een "neem contact op"-pagina. Presenteer in plaats van open toegang een stap-up verificatie. De scraper krijgt niets waarvoor het kwam, maar een echte klant die toevallig wordt gemarkeerd kan het proces alsnog via een alternatief pad afronden.
Hoe cside je website beschermt tegen AI-agent content scrapers

cside is een webbeveiligingsplatform gespecialiseerd in het monitoren van de browserruntime. cside's AI-agentdetectie is specifiek gebouwd om frauduleuze AI-agents op je website te identificeren. Met cside:
- Krijg een dashboard van welke agents je site bezoeken en wat ze doen
- Automatische risicoscores op basis van gedragssignalen om kwaadaardige AI-agents te vangen (inclusief browsergebaseerde en lokaal gehoste) die traditionele botverdedigingen ontwijken
- Stuur detectiesignalen door naar je eigen handhavingsworkflows
- Voorkom AI-agentfraude zoals misbruik van promotiecodes, content-piraterij, creditcardtesten, kwetsbaarheidsontdekking en geavanceerde scraping







