TL;DR
- Detecting AI agent content scrapers requires cross-referencing four signal layers: identity, network, browser environment, and behavioral signals.
- Most companies use an AI agent detection tool like cside or Fingerprint to catch these sessions and inform enforcement actions.
- AI content scraping bots use AI capabilities (e.g. LLM powered extraction or browser agents) to harvest website content.
- Traditional bot detection fails to catch them because these scrapers run from residential IPs, execute JavaScript, and solve CAPTCHAs.
What are AI agent based content scraping bots?

AI content scraping bots use AI capabilities (e.g. LLM powered extraction or browser agents) to harvest website content. They are distinct from traditional scrapers: They use real browsers, adapt when page layouts change, and extract structured meaning rather than just raw HTML.
The AI scraper spectrum
| Scraper type | Identifies itself? | Follows the rules? | How to handle |
|---|---|---|---|
| Training crawlers (GPTBot, ClaudeBot, CCBot) | Yes | Usually | Block or allow in robots.txt |
| Search bots (ChatGPT-User, PerplexityBot) | Yes | Yes | Allow if you want AI search visibility |
| Aggressive crawlers (Bytespider) | Sometimes | Sometimes | Block via robots.txt + IP ranges |
| Commercial scraping tools | No | No | Requires behavioral detection |
| Autonomous AI agents | No | No | Requires behavioral detection |
In 2026, the vast majority of AI agent traffic to your website is still crawlers from major LLM platforms (Claude, ChatGPT, Google). This is what comes to mind when most people think of "AI scrapers". This article will touch on these, but our main focus will be the harder problem: purpose built scrapers made to harvest specific info from your website.
Malicious AI scrapers
- Competitive pricing surveillance that runs through your product pages or quote flows to understand your pricing model. Deployed by competitors or aggregation platforms.
- Content piracy and republishing copies your original content to resell or republish it somewhere else. This hits publishers, research firms, and any company where the content itself is the product.
- Inventory arbitrage (e.g. ticket scalping) bots watch your stock levels and pricing for anything in limited supply, then use that intelligence to buy before real customers or flip it on resale markets. Run by scalper networks and resale operations.
- Lead generation scrapers that pull contact details or user profiles off your platform and sell them as lead lists. Operated by data brokers and lead generation companies.
Major LLM platform scrapers
There are two types here: search bots (like ChatGPT-User and PerplexityBot) that read your pages so they can reference you in AI search results, and training crawlers (like GPTBot, ClaudeBot, and Bytespider) that consume your content to improve their models.
For most companies, this is not the urgent problem. You allow the search bots, block the trainers if it makes sense for you, and move on. We break this down in our guide to blocking AI agent traffic (including why robots.txt on its own is not enough).
How to detect AI agent content scraping bots
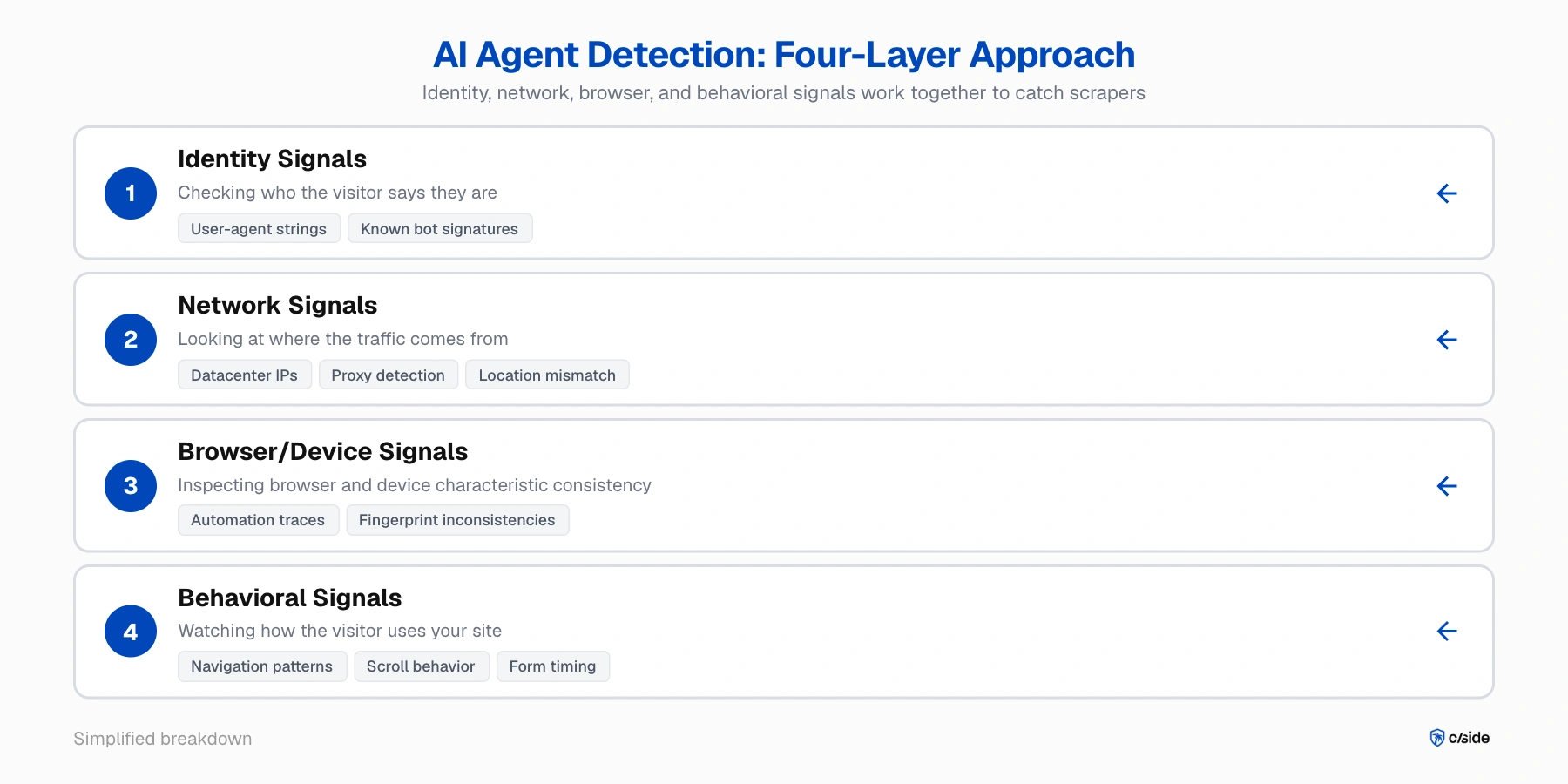
A combination of network, browser, and behavioral signals are needed
No one signal catches a stealthy scraper. The detection methodology we use at cside (for our own platform and for our customers) uses four signal layers evaluated together:
- Identity signals; checking who the visitor says they are. Known crawlers like GPTBot announce themselves with user-agent strings. Other automated bots such as those from Browserbase have a bot signature you can verify.
- Network signals; looking at where the traffic comes from. Is it a datacenter IP? A known proxy? Does the claimed location match the browser's timezone? This catches some basic setups, but sophisticated operations rotate residential IPs that look clean.
- Browser/device signals; inspecting whether browser and device characteristics are consistent. Automation tools like Playwright leave traces in the browser runtime. When fingerprinting details (graphics rendering, audio processing, screen specs) don't tell a coherent story, something has been tampered with.
- Behavioral signals; watching how the visitor uses your site. Navigation patterns, scroll behavior, click placement, form fill timing, and session-level request sequencing. AI-agent bots are much better at masking this than traditional bots, but with detailed monitoring they are still caught.
This bullet point list is condensed for simplicity. If you want a deeper breakdown we have a full article on how to detect AI agent traffic where we elaborate on some of the specific signals that cside engineers deploy in our detection platform.
Specialized vendor tools to detect fraudulent AI agents
If you're worried about AI agent content scrapers and want to stop them, you fundamentally have two choices. Buy, or DIY. Our perspective on trying to solve this with DIY tooling (building it yourself) is simple: don't. Bot security software is a category that teams do not often try to engineer (or vibe code) for very straightforward reasons.
It's a cat and mouse game. Your detection approach will be reverse engineered by the automation platforms. Your team has to continuously update the detection philosophy.
An AI agent detection tool focused on fraud detection is a much easier approach.
cside is one of those vendors, but to keep our educational articles objective we frequently mention other vendors (such as HUMAN and Fingerprint).
But aren't vendor tools extremely expensive and meant for enterprises?
Many of them are (DataDome, HUMAN), as we covered in our comparison guide: 4 Tools To Detect AI Agents On Your Website. But there are options like cside and Fingerprint that have lower priced business plans (starting at $99/month) with the option to send data signals to your anti-fraud workflows via an API. That means you pay only for what you use and you have flexibility on what to do with the detection data.
That way you don't end up paying enterprise pricing for bells and whistles that you don't care about. You can also pilot the detection mechanisms without being locked into a contract.
What AI scrapers target on your website
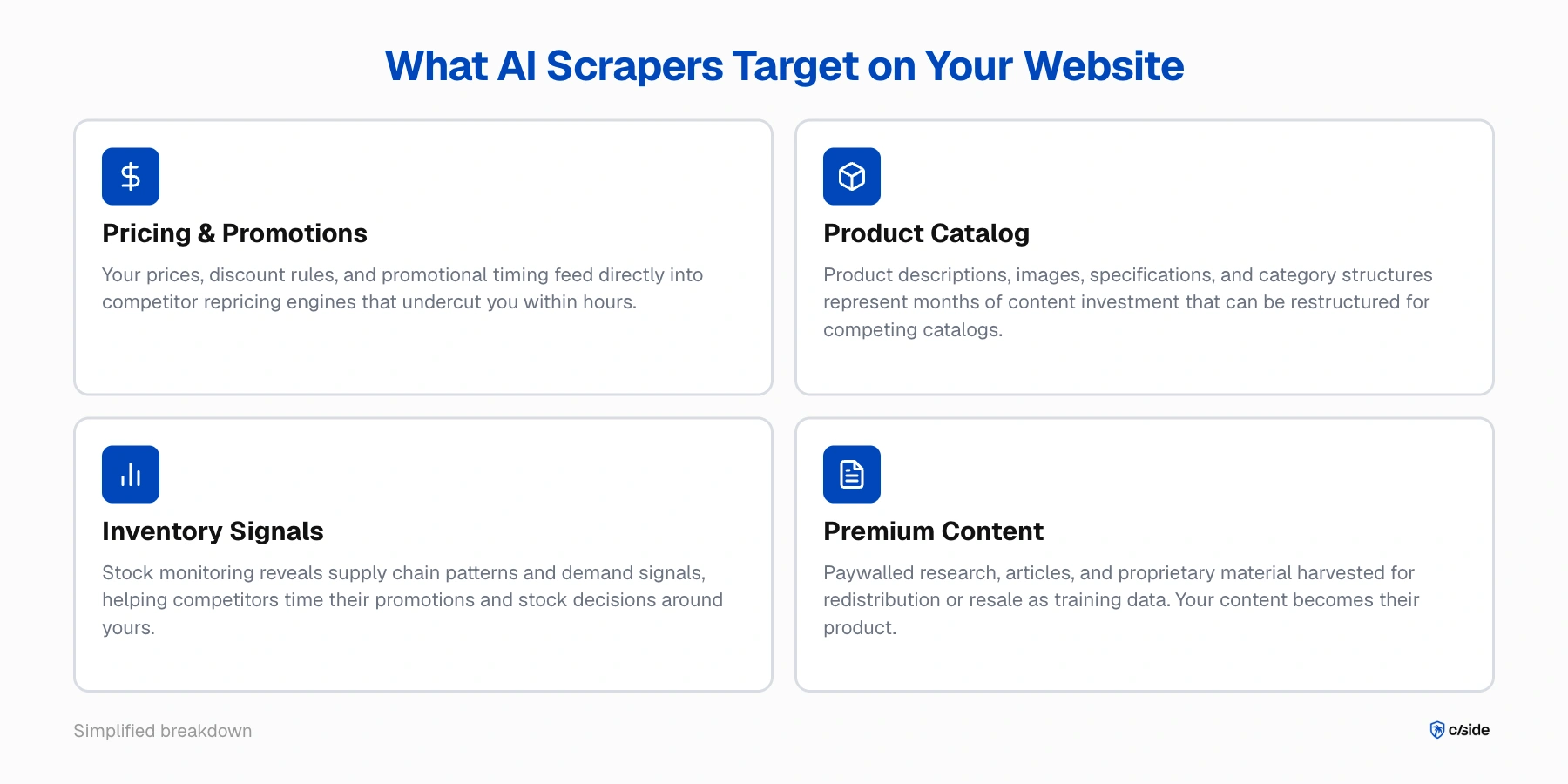
- Pricing and promotional data. Your prices, discount rules, and promotional timing are real-time competitive intelligence. A scraper running through your catalog or quote flows can feed that data straight into a repricing engine that undercuts you within hours.
- Product catalog and content. Your product descriptions, images, specifications, and category structures represent months or years of content investment. AI scrapers can ingest all of it and restructure it for a competing catalog.
- Inventory signals. Repeated monitoring of what is in stock and what is not reveals your supply chain patterns and demand signals. That information is valuable to competitors trying to time their own promotions or stock decisions around yours.
- Proprietary research and premium content. For publishers, research firms, and content businesses, scrapers harvest paywalled material for redistribution or resale as training data. Your content becomes someone else's product.
Example: AI agent based content scraping on an insurance platform
Here's a firsthand example we worked through with one of our customers:
- An insurance company suspects someone is scraping their quotes. Sessions keep filling out the full quoting flow, getting the final price, and leaving without buying. They had basic bot detection in place and it indicated that there was indeed increased bot activity but most of them were getting through, unenforced.
- They implement cside's AI agent detection API. Immediately, bots that were slipping through other defense layers were picked up. The signals were connected to the insurance platform's anti-fraud workflows. A bot risk classification field was used to inform their enforcement decisions.
- When a session is flagged as a likely malicious AI agent, the final step shows a "contact us" page instead of the actual quote. The scraper gets nothing useful. But if it happens to be a real person they can still finish the process. No pricing data leaks to competitors or aggregation platforms and no real customer is turned away.
Since the goal was to "stop malicious price scraping" and not just to detect AI agents, this insurance platform also used cside to catch sign ups with disposable email addresses.
Traditional bot detection fails against AI agent driven content scrapers
Traditional bot detection was built to catch traffic with predicted automated signals: Patterned activity. Requests from datacenter IPs with no browser environment. Many of them could be stopped with a simple CAPTCHA. What makes AI bots different:
- Locally hosted automation. AI scraping agents increasingly run on real consumer hardware rather than cloud servers. A Playwright instance running on a Mac Mini sends requests from a residential IP with authentic device fingerprints.
- They use real browsers. They run inside actual Chrome instances that render your pages, execute your JavaScript, and behave exactly like a customer's browser would.
- They are built to act like people. AI agents randomize their timing, vary their scrolling, and even solve CAPTCHAs.
The fraud costs of content scraping
Content scraping is not the kind of attack that sets off alarms. There is no outage, no ransom note, no dramatic incident. The damage is quieter: a competitor that always matches your prices within hours, a knockoff store selling products with your exact descriptions, an aggregation platform publishing your proprietary data. Aberdeen Research estimated that scraping costs e-commerce businesses between 3% and 14% of annual website revenue, and that the median impact can eat up to 80% of a site's overall profitability.
What makes this harder to stomach is the asymmetry. Running a scraping operation costs a few hundred dollars a month. The revenue it drains from the target can be orders of magnitude higher. And most organizations cannot even quantify how much is being scraped because they lack the visibility to measure it.
Enforcement strategies for AI agent based content scraping
Do not default to blocking everything. The instinct is to block anything that looks automated but that creates two problems. You tip off the scraper that your detection works, so they adapt. And you risk blocking real customers, especially during high-traffic periods when false positive rates climb.
Serve a bot-specific flow instead. The smarter play is to swap what the scraper sees. Instead of a final price show a "contact us" page. Instead of open access present a step-up verification. The scraper gets nothing it came for but a real customer who happens to get flagged can still complete the process through an alternative path.
How cside protects your website from AI agent content scrapers

cside is a web security platform specialized in watching the browser runtime. cside's AI agent detection is purpose-built to identify fraudulent AI agents on your website. With cside:
- Get a dashboard of which agents are accessing your site and what they are doing
- Automatic risk scores from behavioral signals to catch bad AI agents (including browser based and locally hosted ones) that evade traditional bot defenses
- Feed detection signals into your own enforcement action workflows
- Prevent AI agent fraud such as promo code abuse, content piracy, credit card testing, vulnerability discovery, and advanced scraping