

En résumé
- Détecter les scrapers de contenu basés sur des agents IA nécessite de croiser quatre couches de signaux : identité, réseau, environnement du navigateur et signaux comportementaux.
- La plupart des entreprises utilisent un outil de détection d'agents IA comme cside ou Fingerprint pour identifier ces sessions et déclencher des actions d'application.
- Les bots de scraping de contenu IA utilisent des capacités d'IA (extraction par LLM ou agents navigateur) pour collecter le contenu des sites web.
- La détection traditionnelle de bots échoue à les repérer car ces scrapers opèrent depuis des IP résidentielles, exécutent JavaScript et résolvent les CAPTCHAs.
Que sont les bots de scraping de contenu basés sur des agents IA ?

Les bots de scraping de contenu IA utilisent des capacités d'IA (extraction par LLM ou agents navigateur) pour collecter le contenu des sites web. Ils se distinguent des scrapers traditionnels : ils utilisent de vrais navigateurs, s'adaptent lorsque la mise en page change et extraient du sens structuré plutôt que du simple HTML brut.
Le spectre des scrapers IA
| Type de scraper | S'identifie ? | Respecte les règles ? | Comment réagir |
|---|---|---|---|
| Crawlers d'entraînement (GPTBot, ClaudeBot, CCBot) | Oui | Généralement | Bloquer ou autoriser via robots.txt |
| Bots de recherche (ChatGPT-User, PerplexityBot) | Oui | Oui | Autoriser si vous souhaitez la visibilité dans la recherche IA |
| Crawlers agressifs (Bytespider) | Parfois | Parfois | Bloquer via robots.txt + plages d'IP |
| Outils de scraping commerciaux | Non | Non | Nécessite une détection comportementale |
| Agents IA autonomes | Non | Non | Nécessite une détection comportementale |
En 2026, la grande majorité du trafic d'agents IA sur votre site provient encore des crawlers des grandes plateformes LLM (Claude, ChatGPT, Google). C'est ce à quoi la plupart des gens pensent quand ils entendent « scrapers IA ». Cet article abordera ces cas, mais notre focus principal sera le problème plus complexe : les scrapers construits sur mesure pour collecter des informations spécifiques sur votre site.
Scrapers IA malveillants
- Surveillance concurrentielle des prix qui parcourt vos pages produits ou vos flux de devis pour comprendre votre modèle tarifaire. Déployée par des concurrents ou des plateformes d'agrégation.
- Piratage et republication de contenu copie votre contenu original pour le revendre ou le republier ailleurs. Cela touche les éditeurs, les cabinets de recherche et toute entreprise dont le contenu est le produit.
- Arbitrage d'inventaire (ex. scalping de billets) — des bots surveillent vos niveaux de stock et vos prix pour tout ce qui est en quantité limitée, puis utilisent cette intelligence pour acheter avant les vrais clients ou revendre sur les marchés secondaires. Opéré par des réseaux de scalpers et des opérations de revente.
- Génération de leads — des scrapers qui extraient les coordonnées ou les profils utilisateurs de votre plateforme et les revendent comme listes de prospects. Opéré par des courtiers en données et des entreprises de génération de leads.
Scrapers des grandes plateformes LLM
Il existe deux types ici : les bots de recherche (comme ChatGPT-User et PerplexityBot) qui lisent vos pages pour vous référencer dans les résultats de recherche IA, et les crawlers d'entraînement (comme GPTBot, ClaudeBot et Bytespider) qui consomment votre contenu pour améliorer leurs modèles.
Pour la plupart des entreprises, ce n'est pas le problème urgent. Vous autorisez les bots de recherche, bloquez les crawlers d'entraînement si cela a du sens pour vous, et passez à autre chose. Nous détaillons cela dans notre guide sur le blocage du trafic d'agents IA (y compris pourquoi robots.txt seul ne suffit pas).
Comment détecter les bots de scraping de contenu basés sur des agents IA
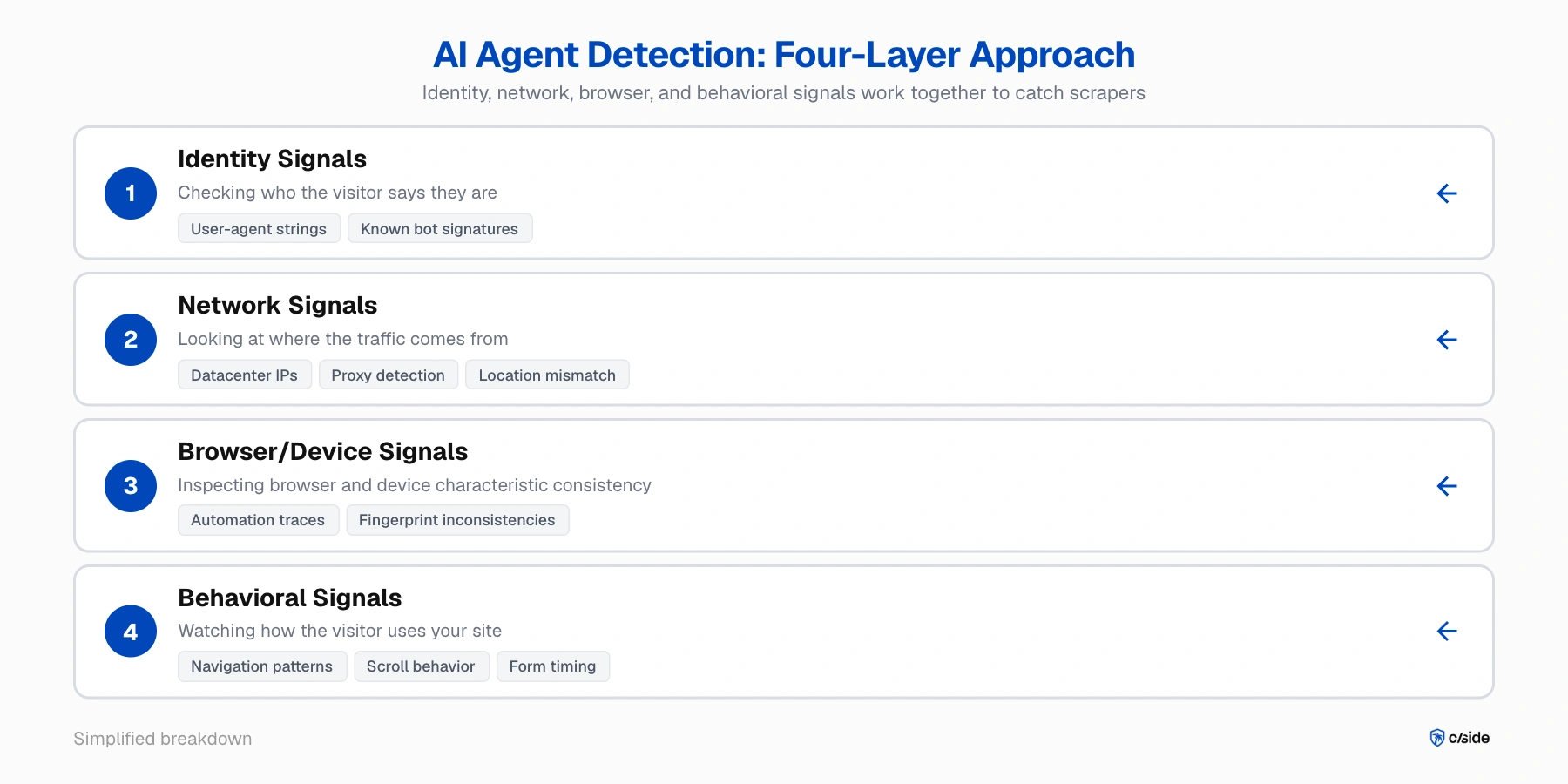
Une combinaison de signaux réseau, navigateur et comportementaux est nécessaire
Aucun signal unique ne détecte un scraper furtif. La méthodologie de détection que nous utilisons chez cside (pour notre propre plateforme et pour nos clients) repose sur quatre couches de signaux évaluées ensemble :
- Signaux d'identité; vérifier qui le visiteur prétend être. Les crawlers connus comme GPTBot s'annoncent via des chaînes user-agent. D'autres bots automatisés comme ceux de Browserbase ont une signature bot que vous pouvez vérifier.
- Signaux réseau; analyser d'où provient le trafic. Est-ce une IP de datacenter ? Un proxy connu ? La localisation déclarée correspond-elle au fuseau horaire du navigateur ? Cela détecte certaines configurations basiques, mais les opérations sophistiquées utilisent des IP résidentielles qui paraissent légitimes.
- Signaux navigateur/appareil; inspecter si les caractéristiques du navigateur et de l'appareil sont cohérentes. Les outils d'automatisation comme Playwright laissent des traces dans le runtime du navigateur. Lorsque les détails de fingerprinting (rendu graphique, traitement audio, spécifications d'écran) ne racontent pas une histoire cohérente, quelque chose a été falsifié.
- Signaux comportementaux; observer comment le visiteur utilise votre site. Schémas de navigation, comportement de défilement, positionnement des clics, timing de remplissage des formulaires et séquençage des requêtes au niveau de la session. Les bots d'agents IA sont bien meilleurs pour masquer cela que les bots traditionnels, mais avec une surveillance détaillée, ils sont tout de même détectés.
Cette liste est condensée par souci de simplicité. Si vous souhaitez un examen plus approfondi, nous avons un article complet sur comment détecter le trafic d'agents IA où nous détaillons certains des signaux spécifiques que les ingénieurs de cside déploient dans notre plateforme de détection.
Outils spécialisés de fournisseurs pour détecter les agents IA frauduleux
Si vous êtes préoccupé par les scrapers de contenu basés sur des agents IA et souhaitez les arrêter, vous avez fondamentalement deux choix. Acheter, ou faire soi-même. Notre perspective sur la résolution de ce problème avec des outils DIY (les construire vous-même) est simple : ne le faites pas. La sécurité anti-bots est une catégorie que les équipes n'essaient pas souvent de développer en interne pour des raisons très évidentes.
C'est un jeu du chat et de la souris. Votre approche de détection sera rétro-ingéniée par les plateformes d'automatisation. Votre équipe doit continuellement mettre à jour la philosophie de détection.
Un outil de détection d'agents IA spécialisé dans la détection de fraude est une approche bien plus simple.
cside est l'un de ces fournisseurs, mais pour garder nos articles éducatifs objectifs, nous mentionnons fréquemment d'autres fournisseurs (comme HUMAN et Fingerprint).
Mais ces outils ne sont-ils pas extrêmement chers et destinés aux entreprises ?
Beaucoup le sont (DataDome, HUMAN), comme nous l'avons couvert dans notre guide comparatif : 4 outils pour détecter les agents IA sur votre site web. Mais il existe des options comme cside et Fingerprint qui proposent des plans business à prix plus accessible (à partir de 99 $/mois) avec la possibilité d'envoyer des signaux de détection à vos workflows anti-fraude via une API. Cela signifie que vous payez uniquement ce que vous utilisez et que vous avez la flexibilité de décider quoi faire avec les données de détection.
Ainsi, vous ne finissez pas par payer un prix entreprise pour des fonctionnalités superflues qui ne vous intéressent pas. Vous pouvez également piloter les mécanismes de détection sans être engagé dans un contrat.
Ce que les scrapers IA ciblent sur votre site web
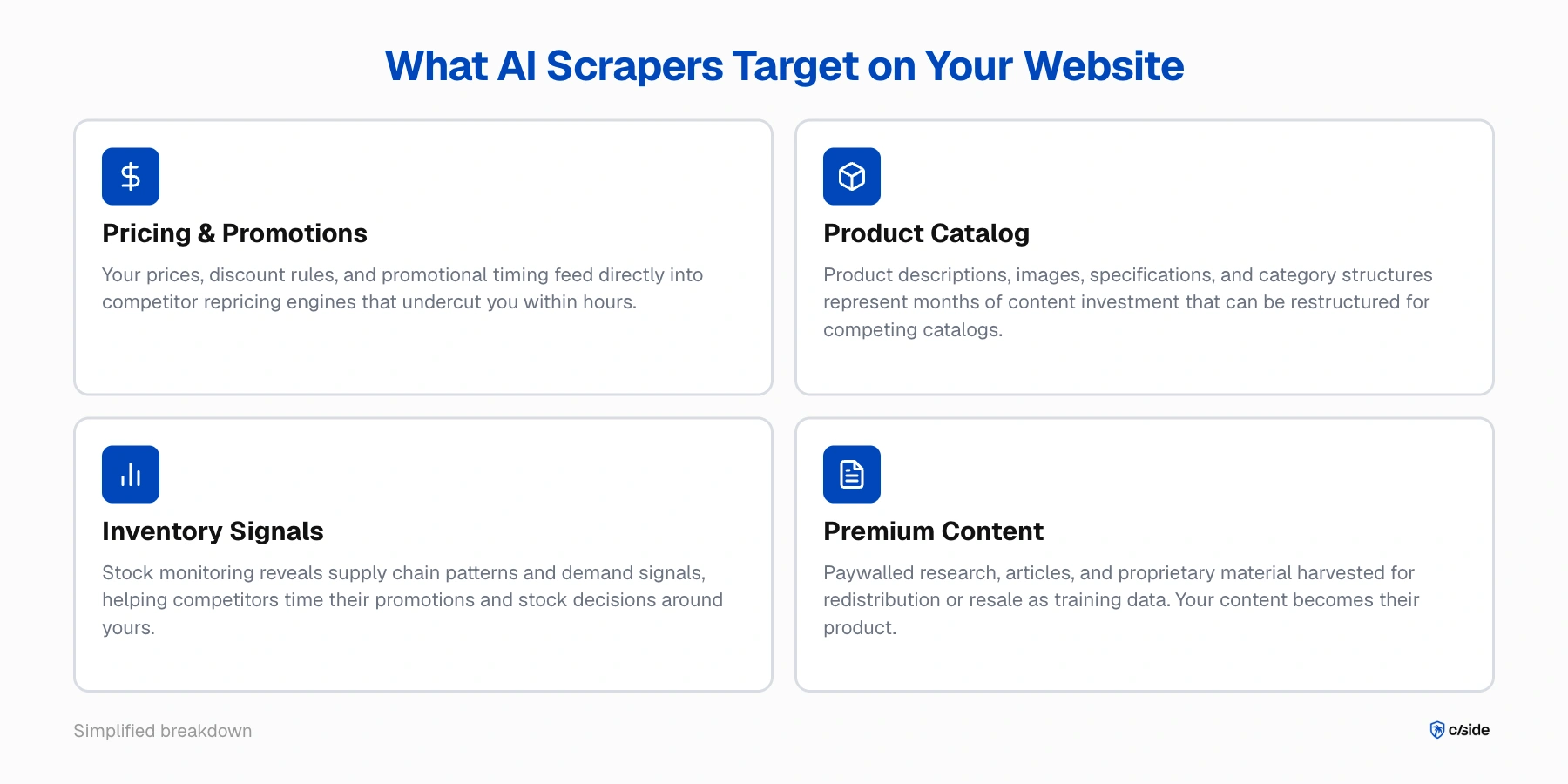
- Données tarifaires et promotionnelles. Vos prix, règles de remise et calendrier promotionnel constituent une intelligence concurrentielle en temps réel. Un scraper parcourant votre catalogue ou vos flux de devis peut alimenter directement un moteur de repricing qui vous sous-cotera en quelques heures.
- Catalogue produits et contenu. Vos descriptions de produits, images, spécifications et structures de catégories représentent des mois ou des années d'investissement en contenu. Les scrapers IA peuvent tout ingérer et le restructurer pour un catalogue concurrent.
- Signaux d'inventaire. La surveillance répétée de ce qui est en stock et de ce qui ne l'est pas révèle vos schémas de chaîne d'approvisionnement et vos signaux de demande. Cette information est précieuse pour des concurrents qui cherchent à planifier leurs propres promotions ou décisions de stock en fonction des vôtres.
- Recherche propriétaire et contenu premium. Pour les éditeurs, cabinets de recherche et entreprises de contenu, les scrapers collectent du matériel protégé par un paywall pour le redistribuer ou le revendre comme données d'entraînement. Votre contenu devient le produit de quelqu'un d'autre.
Exemple : scraping de contenu par agent IA sur une plateforme d'assurance
Voici un exemple concret que nous avons traité avec l'un de nos clients :
- Une compagnie d'assurance soupçonne que quelqu'un scrape ses devis. Des sessions remplissent sans cesse le flux complet de devis, obtiennent le prix final et partent sans acheter. Ils avaient une détection de bots basique en place qui indiquait effectivement une activité bot accrue, mais la plupart passaient à travers sans être bloqués.
- Ils implémentent l'API de détection d'agents IA de cside. Immédiatement, des bots qui échappaient aux autres couches de défense ont été repérés. Les signaux ont été connectés aux workflows anti-fraude de la plateforme d'assurance. Un champ de classification du risque bot a été utilisé pour orienter leurs décisions d'application.
- Lorsqu'une session est signalée comme un agent IA probablement malveillant, la dernière étape affiche une page « contactez-nous » au lieu du devis réel. Le scraper n'obtient rien d'utile. Mais si c'est une vraie personne, elle peut tout de même terminer le processus. Aucune donnée tarifaire ne fuite vers les concurrents ou les plateformes d'agrégation et aucun vrai client n'est rejeté.
Puisque l'objectif était de « stopper le scraping malveillant de prix » et pas seulement de détecter les agents IA, cette plateforme d'assurance a également utilisé cside pour détecter les inscriptions avec des adresses e-mail jetables.
La détection traditionnelle de bots échoue face aux scrapers de contenu pilotés par des agents IA
La détection traditionnelle de bots a été conçue pour intercepter le trafic présentant des signaux automatisés prévisibles : activité avec des patterns. Requêtes depuis des IP de datacenter sans environnement navigateur. Beaucoup pouvaient être stoppés avec un simple CAPTCHA. Ce qui rend les bots IA différents :
- Automatisation hébergée localement. Les agents de scraping IA s'exécutent de plus en plus sur du matériel grand public plutôt que sur des serveurs cloud. Une instance Playwright tournant sur un Mac Mini envoie des requêtes depuis une IP résidentielle avec des empreintes d'appareil authentiques.
- Ils utilisent de vrais navigateurs. Ils s'exécutent dans de véritables instances Chrome qui rendent vos pages, exécutent votre JavaScript et se comportent exactement comme le navigateur d'un client.
- Ils sont conçus pour agir comme des humains. Les agents IA randomisent leur timing, varient leur défilement et résolvent même les CAPTCHAs.
Les coûts de fraude du scraping de contenu
Le scraping de contenu n'est pas le type d'attaque qui déclenche des alarmes. Il n'y a pas de panne, pas de demande de rançon, pas d'incident spectaculaire. Les dommages sont plus discrets : un concurrent qui aligne toujours ses prix sur les vôtres en quelques heures, une boutique contrefaite vendant des produits avec vos descriptions exactes, une plateforme d'agrégation publiant vos données propriétaires. Aberdeen Research a estimé que le scraping coûte aux entreprises e-commerce entre 3 % et 14 % du chiffre d'affaires annuel de leur site web, et que l'impact médian peut absorber jusqu'à 80 % de la rentabilité globale d'un site.
Ce qui rend cela plus difficile à accepter est l'asymétrie. Exploiter une opération de scraping coûte quelques centaines de dollars par mois. Le revenu qu'elle draine de la cible peut être de plusieurs ordres de grandeur supérieur. Et la plupart des organisations ne peuvent même pas quantifier ce qui est scrapé car elles n'ont pas la visibilité nécessaire pour le mesurer.
Stratégies d'application pour le scraping de contenu par agents IA
Ne bloquez pas tout par défaut. L'instinct est de bloquer tout ce qui semble automatisé, mais cela crée deux problèmes. Vous alertez le scraper que votre détection fonctionne, donc il s'adapte. Et vous risquez de bloquer de vrais clients, surtout pendant les périodes de forte affluence lorsque les taux de faux positifs augmentent.
Servez un flux spécifique aux bots à la place. La stratégie la plus intelligente est de modifier ce que le scraper voit. Au lieu d'un prix final, affichez une page « contactez-nous ». Au lieu d'un accès libre, présentez une vérification renforcée. Le scraper n'obtient rien de ce qu'il cherchait, mais un vrai client qui se retrouve signalé peut toujours compléter le processus via un parcours alternatif.
Comment cside protège votre site web contre les scrapers de contenu par agents IA

cside est une plateforme de sécurité web spécialisée dans la surveillance du runtime navigateur. La détection d'agents IA de cside est conçue spécifiquement pour identifier les agents IA frauduleux sur votre site web. Avec cside :
- Obtenez un tableau de bord indiquant quels agents accèdent à votre site et ce qu'ils font
- Scores de risque automatiques basés sur les signaux comportementaux pour détecter les agents IA malveillants (y compris ceux basés sur navigateur et hébergés localement) qui échappent aux défenses anti-bots traditionnelles
- Alimentez les signaux de détection dans vos propres workflows d'actions d'application
- Prévenez la fraude par agents IA telle que l'abus de codes promo, le piratage de contenu, le test de cartes bancaires, la découverte de vulnérabilités et le scraping avancé







