

Resumo
- Detectar scrapers de conteúdo baseados em agentes de IA requer o cruzamento de quatro camadas de sinais: identidade, rede, ambiente do navegador e sinais comportamentais.
- A maioria das empresas usa uma ferramenta de detecção de agentes de IA como o cside ou Fingerprint para capturar essas sessões e orientar ações de enforcement.
- Bots de scraping de conteúdo com IA utilizam capacidades de IA (como extração com LLM ou agentes de navegador) para coletar conteúdo de sites.
- A detecção tradicional de bots não consegue capturá-los porque esses scrapers operam a partir de IPs residenciais, executam JavaScript e resolvem CAPTCHAs.
O que são bots de scraping de conteúdo baseados em agentes de IA?

Bots de scraping de conteúdo com IA utilizam capacidades de IA (como extração com LLM ou agentes de navegador) para coletar conteúdo de sites. Eles são distintos dos scrapers tradicionais: usam navegadores reais, se adaptam quando os layouts das páginas mudam e extraem significado estruturado em vez de apenas HTML bruto.
O espectro dos scrapers de IA
| Tipo de scraper | Se identifica? | Segue as regras? | Como lidar |
|---|---|---|---|
| Crawlers de treinamento (GPTBot, ClaudeBot, CCBot) | Sim | Geralmente | Bloquear ou permitir no robots.txt |
| Bots de busca (ChatGPT-User, PerplexityBot) | Sim | Sim | Permitir se quiser visibilidade em buscas com IA |
| Crawlers agressivos (Bytespider) | Às vezes | Às vezes | Bloquear via robots.txt + faixas de IP |
| Ferramentas comerciais de scraping | Não | Não | Requer detecção comportamental |
| Agentes de IA autônomos | Não | Não | Requer detecção comportamental |
Em 2026, a grande maioria do tráfego de agentes de IA no seu site ainda vem de crawlers das principais plataformas de LLM (Claude, ChatGPT, Google). Isso é o que vem à mente quando a maioria das pessoas pensa em "scrapers de IA". Este artigo abordará esses casos, mas nosso foco principal será o problema mais difícil: scrapers construídos especificamente para coletar informações específicas do seu site.
Scrapers de IA maliciosos
- Vigilância competitiva de preços que percorre suas páginas de produtos ou fluxos de cotação para entender seu modelo de preços. Utilizado por concorrentes ou plataformas de agregação.
- Pirataria e republicação de conteúdo copia seu conteúdo original para revender ou republicar em outro lugar. Isso afeta editoras, empresas de pesquisa e qualquer empresa onde o conteúdo em si é o produto.
- Arbitragem de estoque (por exemplo, cambismo de ingressos) bots monitoram seus níveis de estoque e preços de itens com oferta limitada, depois usam essa inteligência para comprar antes dos clientes reais ou revender em mercados secundários. Operados por redes de cambistas e operações de revenda.
- Geração de leads scrapers que extraem detalhes de contato ou perfis de usuários da sua plataforma e os vendem como listas de leads. Operados por corretores de dados e empresas de geração de leads.
Scrapers das principais plataformas de LLM
Existem dois tipos aqui: bots de busca (como ChatGPT-User e PerplexityBot) que leem suas páginas para poder referenciá-lo nos resultados de busca com IA, e crawlers de treinamento (como GPTBot, ClaudeBot e Bytespider) que consomem seu conteúdo para melhorar seus modelos.
Para a maioria das empresas, esse não é o problema urgente. Você permite os bots de busca, bloqueia os de treinamento se fizer sentido para você e segue em frente. Detalhamos isso no nosso guia sobre bloqueio de tráfego de agentes de IA (incluindo por que o robots.txt sozinho não é suficiente).
Como detectar bots de scraping de conteúdo baseados em agentes de IA
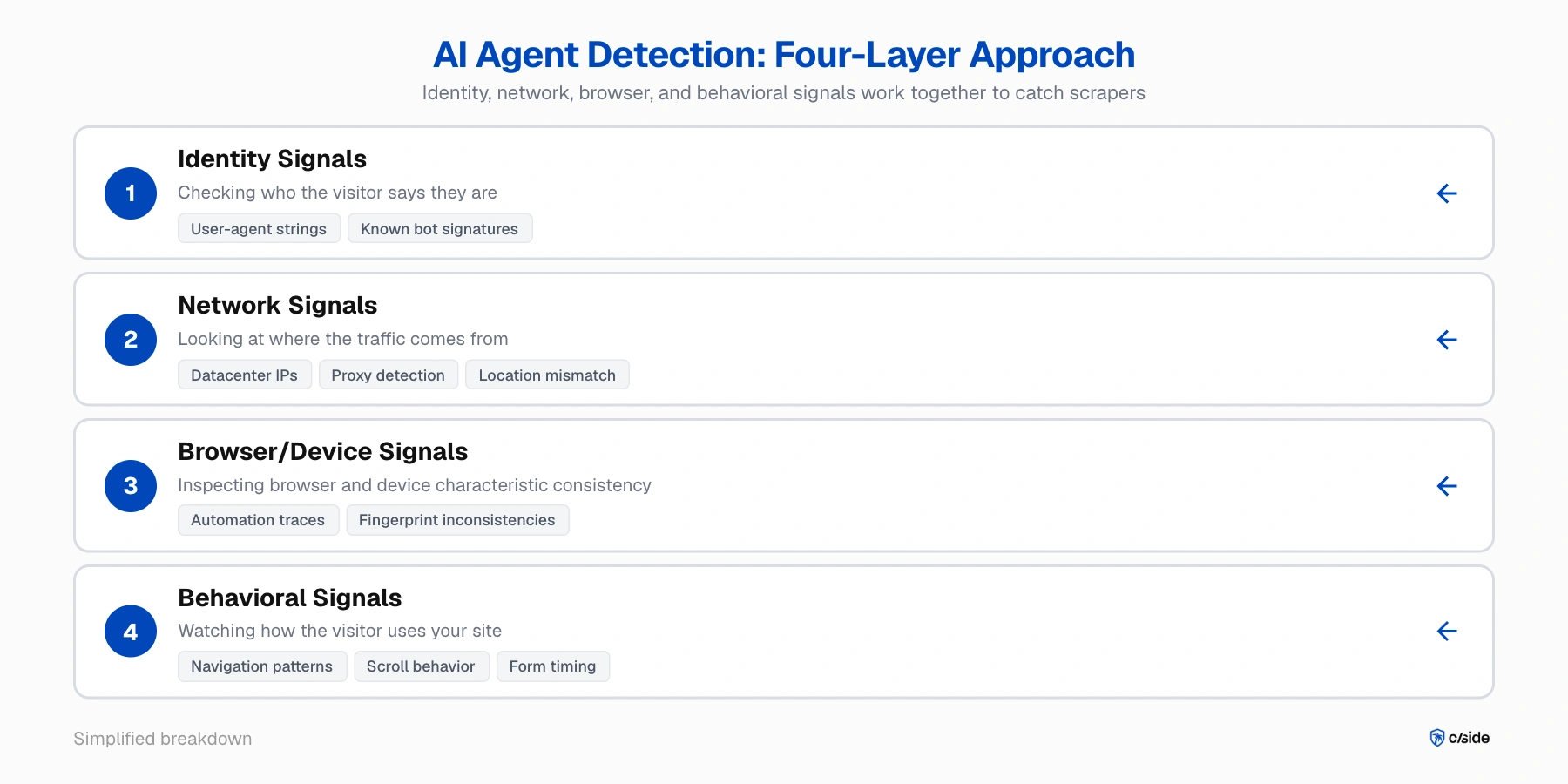
Uma combinação de sinais de rede, navegador e comportamento é necessária
Nenhum sinal isolado captura um scraper furtivo. A metodologia de detecção que usamos no cside (para nossa própria plataforma e para nossos clientes) utiliza quatro camadas de sinais avaliadas em conjunto:
- Sinais de identidade; verificando quem o visitante diz ser. Crawlers conhecidos como GPTBot se anunciam com strings de user-agent. Outros bots automatizados, como os da Browserbase, têm uma assinatura de bot que você pode verificar.
- Sinais de rede; analisando de onde o tráfego vem. É um IP de datacenter? Um proxy conhecido? A localização declarada corresponde ao fuso horário do navegador? Isso captura algumas configurações básicas, mas operações sofisticadas rotacionam IPs residenciais que parecem legítimos.
- Sinais de navegador/dispositivo; inspecionando se as características do navegador e do dispositivo são consistentes. Ferramentas de automação como Playwright deixam rastros no runtime do navegador. Quando os detalhes de fingerprinting (renderização gráfica, processamento de áudio, especificações de tela) não contam uma história coerente, algo foi adulterado.
- Sinais comportamentais; observando como o visitante usa seu site. Padrões de navegação, comportamento de rolagem, posicionamento de cliques, tempo de preenchimento de formulários e sequenciamento de requisições no nível da sessão. Bots de agentes de IA são muito melhores em mascarar isso do que bots tradicionais, mas com monitoramento detalhado ainda são capturados.
Esta lista é condensada para simplificar. Se quiser uma análise mais aprofundada, temos um artigo completo sobre como detectar tráfego de agentes de IA onde elaboramos alguns dos sinais específicos que os engenheiros do cside implementam em nossa plataforma de detecção.
Ferramentas especializadas de fornecedores para detectar agentes de IA fraudulentos
Se você está preocupado com scrapers de conteúdo baseados em agentes de IA e quer pará-los, você fundamentalmente tem duas opções. Comprar ou fazer você mesmo. Nossa perspectiva sobre tentar resolver isso com ferramentas DIY (construindo você mesmo) é simples: não faça. Software de segurança contra bots é uma categoria que equipes não costumam tentar desenvolver (ou fazer com vibe coding) por razões bastante diretas.
É um jogo de gato e rato. Sua abordagem de detecção será engenharia reversa pelas plataformas de automação. Sua equipe precisa atualizar continuamente a filosofia de detecção.
Uma ferramenta de detecção de agentes de IA focada em detecção de fraude é uma abordagem muito mais fácil.
O cside é um desses fornecedores, mas para manter nossos artigos educacionais objetivos, frequentemente mencionamos outros fornecedores (como HUMAN e Fingerprint).
Mas as ferramentas de fornecedores não são extremamente caras e voltadas para empresas?
Muitas delas são (DataDome, HUMAN), como abordamos no nosso guia comparativo: 4 Ferramentas Para Detectar Agentes de IA No Seu Site. Mas existem opções como o cside e o Fingerprint que têm planos empresariais com preços mais acessíveis (a partir de $99/mês) com a opção de enviar sinais de dados para seus fluxos antifraude via API. Isso significa que você paga apenas pelo que usa e tem flexibilidade sobre o que fazer com os dados de detecção.
Dessa forma, você não acaba pagando preços corporativos por recursos extras que não precisa. Você também pode pilotar os mecanismos de detecção sem estar preso a um contrato.
O que os scrapers de IA buscam no seu site
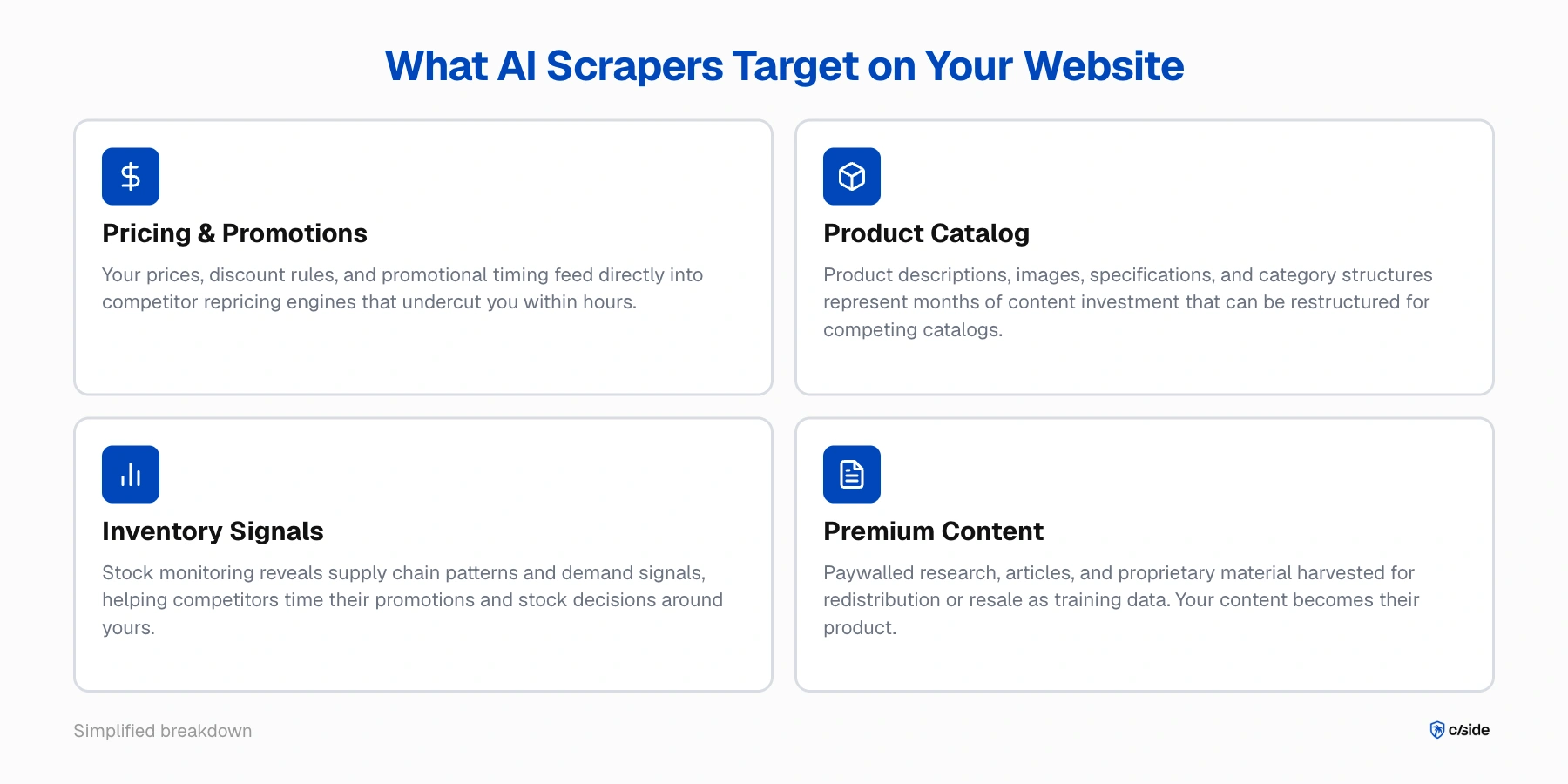
- Dados de preços e promoções. Seus preços, regras de desconto e cronogramas promocionais são inteligência competitiva em tempo real. Um scraper percorrendo seu catálogo ou fluxos de cotação pode alimentar esses dados diretamente em um motor de reprecificação que te subcota em questão de horas.
- Catálogo de produtos e conteúdo. Suas descrições de produtos, imagens, especificações e estruturas de categorias representam meses ou anos de investimento em conteúdo. Scrapers de IA podem absorver tudo isso e reestruturar para um catálogo concorrente.
- Sinais de estoque. O monitoramento repetido do que está em estoque e do que não está revela seus padrões de cadeia de suprimentos e sinais de demanda. Essa informação é valiosa para concorrentes tentando cronometrar suas próprias promoções ou decisões de estoque baseadas nas suas.
- Pesquisa proprietária e conteúdo premium. Para editoras, empresas de pesquisa e negócios de conteúdo, scrapers coletam material protegido por paywall para redistribuição ou revenda como dados de treinamento. Seu conteúdo se torna o produto de outra pessoa.
Exemplo: scraping de conteúdo baseado em agentes de IA em uma plataforma de seguros
Aqui está um exemplo real que trabalhamos com um dos nossos clientes:
- Uma seguradora suspeita que alguém está fazendo scraping de suas cotações. Sessões continuam preenchendo todo o fluxo de cotação, obtendo o preço final e saindo sem comprar. Eles tinham detecção básica de bots implementada e ela indicava que havia de fato atividade aumentada de bots, mas a maioria passava sem enforcement.
- Eles implementam a API de detecção de agentes de IA do cside. Imediatamente, bots que escapavam de outras camadas de defesa foram capturados. Os sinais foram conectados aos fluxos antifraude da plataforma de seguros. Um campo de classificação de risco de bot foi usado para orientar suas decisões de enforcement.
- Quando uma sessão é sinalizada como provável agente de IA malicioso, a etapa final mostra uma página de "fale conosco" em vez da cotação real. O scraper não obtém nada útil. Mas se por acaso for uma pessoa real, ela ainda pode completar o processo. Nenhum dado de preços vaza para concorrentes ou plataformas de agregação e nenhum cliente real é rejeitado.
Como o objetivo era "parar o scraping malicioso de preços" e não apenas detectar agentes de IA, essa plataforma de seguros também usou o cside para capturar cadastros com endereços de e-mail descartáveis.
A detecção tradicional de bots falha contra scrapers de conteúdo baseados em agentes de IA
A detecção tradicional de bots foi construída para capturar tráfego com sinais automatizados previsíveis: atividade padronizada. Requisições de IPs de datacenter sem ambiente de navegador. Muitos deles podiam ser parados com um simples CAPTCHA. O que torna os bots de IA diferentes:
- Automação hospedada localmente. Agentes de scraping com IA cada vez mais rodam em hardware real de consumo em vez de servidores em nuvem. Uma instância de Playwright rodando em um Mac Mini envia requisições de um IP residencial com fingerprints de dispositivo autênticos.
- Eles usam navegadores reais. Eles rodam dentro de instâncias reais do Chrome que renderizam suas páginas, executam seu JavaScript e se comportam exatamente como o navegador de um cliente faria.
- Eles são construídos para agir como pessoas. Agentes de IA randomizam seus tempos, variam sua rolagem e até resolvem CAPTCHAs.
Os custos de fraude do scraping de conteúdo
O scraping de conteúdo não é o tipo de ataque que dispara alarmes. Não há queda do sistema, não há nota de resgate, não há incidente dramático. O dano é mais silencioso: um concorrente que sempre iguala seus preços em questão de horas, uma loja pirata vendendo produtos com suas descrições exatas, uma plataforma de agregação publicando seus dados proprietários. A Aberdeen Research estimou que o scraping custa às empresas de e-commerce entre 3% e 14% da receita anual do site, e que o impacto mediano pode consumir até 80% da lucratividade geral de um site.
O que torna isso mais difícil de aceitar é a assimetria. Operar uma operação de scraping custa algumas centenas de dólares por mês. A receita que drena do alvo pode ser ordens de magnitude maior. E a maioria das organizações nem consegue quantificar quanto está sendo coletado porque falta visibilidade para medir.
Estratégias de enforcement para scraping de conteúdo baseado em agentes de IA
Não opte por bloquear tudo como padrão. O instinto é bloquear qualquer coisa que pareça automatizada, mas isso cria dois problemas. Você alerta o scraper de que sua detecção funciona, então ele se adapta. E você arrisca bloquear clientes reais, especialmente durante períodos de alto tráfego quando as taxas de falso positivo aumentam.
Sirva um fluxo específico para bots em vez disso. A jogada mais inteligente é trocar o que o scraper vê. Em vez de um preço final, mostre uma página de "fale conosco". Em vez de acesso aberto, apresente uma verificação adicional. O scraper não obtém nada do que veio buscar, mas um cliente real que por acaso seja sinalizado ainda pode completar o processo por um caminho alternativo.
Como o cside protege seu site contra scrapers de conteúdo baseados em agentes de IA

O cside é uma plataforma de segurança web especializada em monitorar o runtime do navegador. A detecção de agentes de IA do cside é construída especificamente para identificar agentes de IA fraudulentos no seu site. Com o cside:
- Obtenha um painel mostrando quais agentes estão acessando seu site e o que estão fazendo
- Pontuações de risco automáticas a partir de sinais comportamentais para capturar agentes de IA maliciosos (incluindo os baseados em navegador e hospedados localmente) que escapam das defesas tradicionais contra bots
- Alimente sinais de detecção nos seus próprios fluxos de ação de enforcement
- Previna fraude de agentes de IA como abuso de códigos promocionais, pirataria de conteúdo, teste de cartões de crédito, descoberta de vulnerabilidades e scraping avançado







