

El 18 de noviembre, Cloudflare sufrió un incidente que afectó a miles de clientes, incluidos clientes que utilizan nuestro servicio. Nuestro servicio de proxy está alojado en AWS con una arquitectura de altísima disponibilidad, que no se vio afectada (ni siquiera por la reciente interrupción de AWS). Además, diseñamos nuestro sistema para ser resiliente ante fallos centralizados y para minimizar el impacto en los clientes en caso de que ocurran.
El incidente duró aproximadamente 5 h 34 min, desde la caída hasta la resolución completa (observamos recuperación a partir de las 3 horas del incidente). Puedes consultar nuestra línea de tiempo del incidente aquí.
Nos gustaría compartir algunas observaciones interesantes durante la interrupción, así como destacar algunos aspectos de nuestra arquitectura que limitaron el impacto en nuestros clientes durante este evento.
Observaciones internas + cómo limitamos el impacto en los clientes
Dado que nuestro proxy y el pipeline de procesamiento interno están alojados en AWS, ninguna de nuestras operaciones críticas se vio afectada. Sin embargo, nuestro dashboard está alojado en Cloudflare, por lo que sí se vio afectado, como le ocurrió a la mayoría de los sitios web en internet. Como utilizamos Cloudflare para el alojamiento (Cloudflare Workers/Pages/etc) y no solo para el proxy, no pudimos simplemente redirigir el DNS para sortear la interrupción. Además, muchos servicios upstream dependen de Cloudflare de una u otra forma. Cuando se necesita una distribución de activos económica a través de una CDN, Cloudflare es la opción natural.
Interrupciones en servicios upstream
Desde nuestra perspectiva, pudimos observar la interrupción desde los servidores upstream. Detectamos un alto número de errores 5XX provenientes de servidores afectados por la interrupción de Cloudflare en nuestro proxy. También recibimos alertas al respecto, y se puede notar que el momento del aumento de errores coincide casi exactamente con el inicio de la interrupción de Cloudflare a las 11:48 UTC.
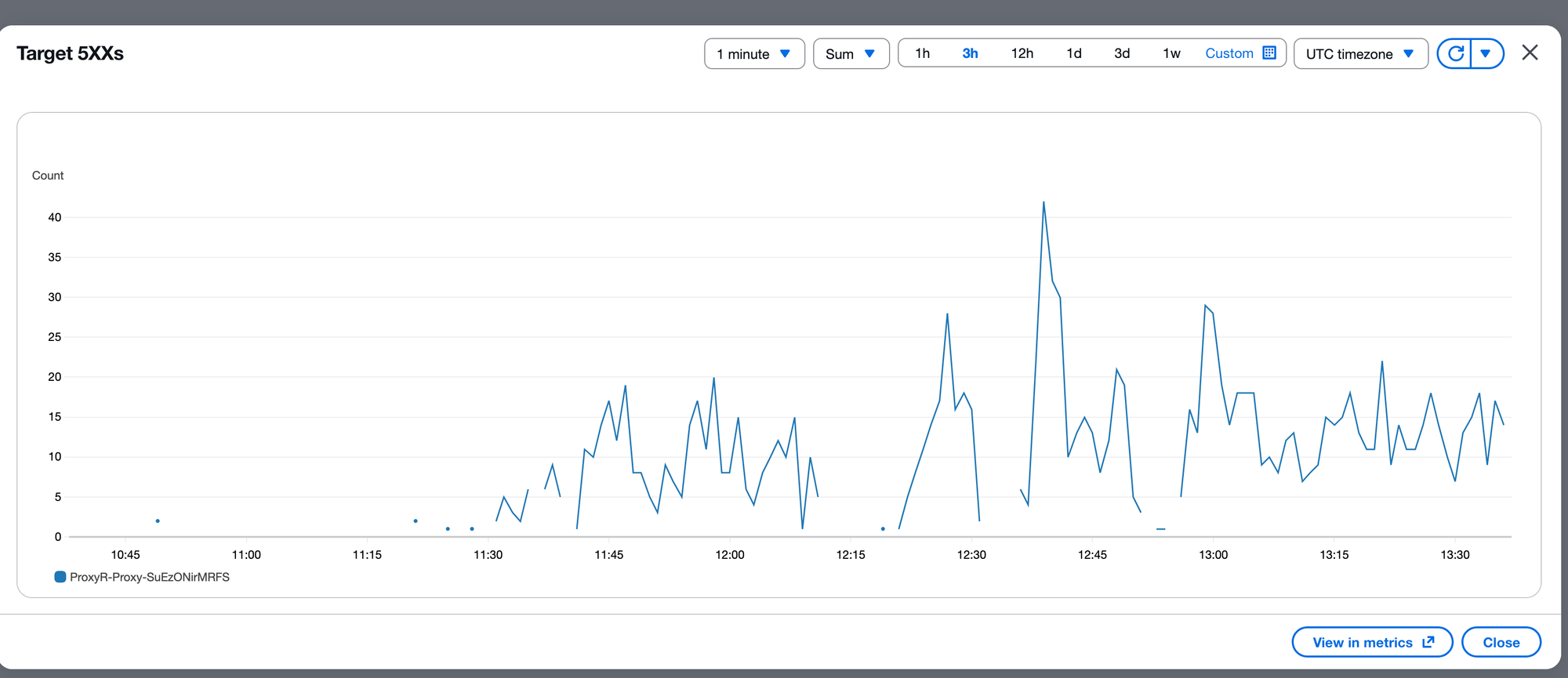
Dado que nuestro proxy pasa por los balanceadores de carga de AWS y devolvemos la misma respuesta HTTP que las fuentes de scripts upstream, obtenemos todas las métricas cuando ocurren interrupciones como esta. Esta es una ventaja de tener el tráfico enrutado a través de nuestro sistema: podemos detectar interrupciones de inmediato y notificar a nuestros clientes sobre el impacto.
Cómo mantuvimos la entrega de scripts durante la interrupción
Almacenamos en caché las solicitudes a scripts idénticos cuando la política de caché (Cache-Control) lo permite, por lo que en este caso los scripts alojados en Cloudflare seguían siendo accesibles y lo serían hasta que la caché se invalidara. Esta es una ventaja de utilizar el proxy de cside.
A continuación se muestra una captura de nuestro dashboard interno de Grafana con las métricas de scripts durante el período de la interrupción.
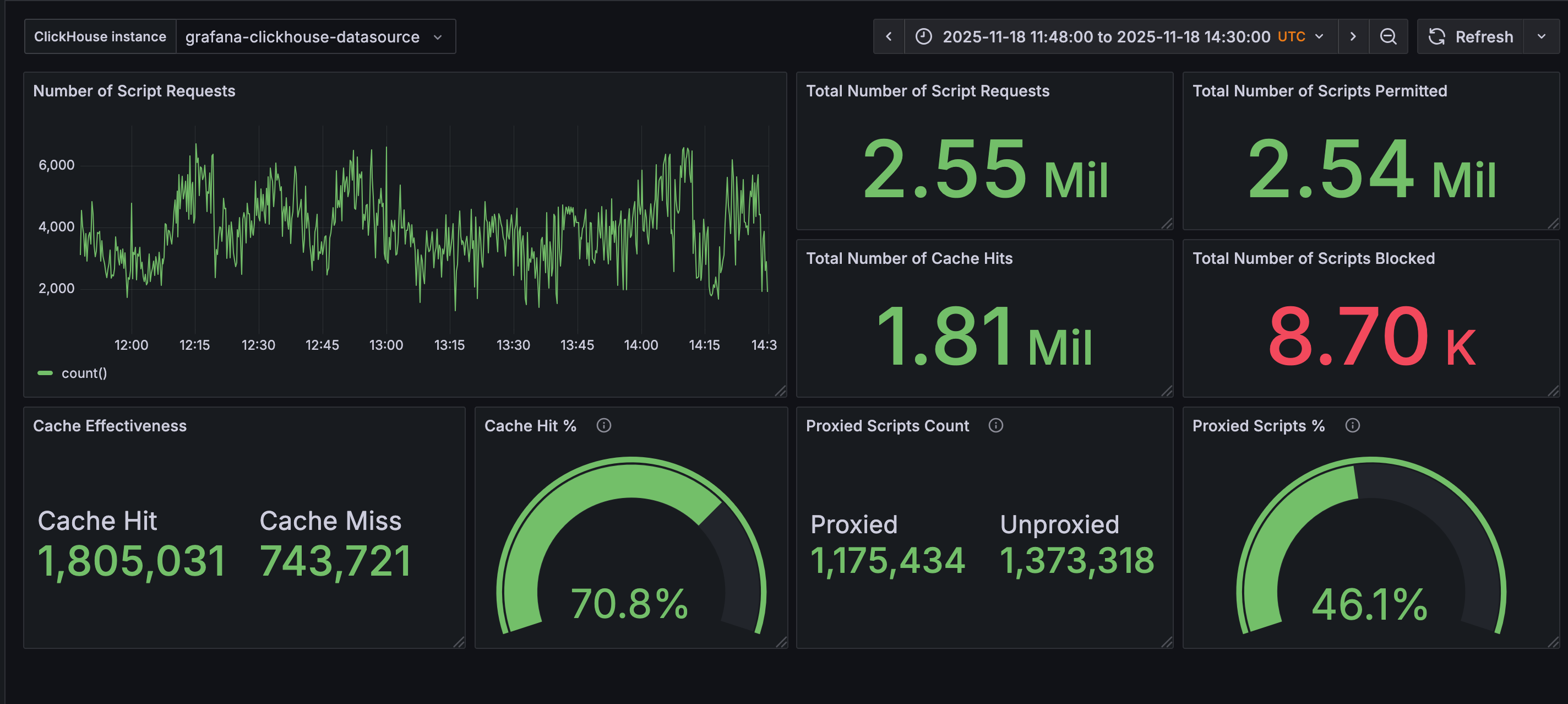
Durante la interrupción: se observa una tasa de aciertos de caché del 70,8 %, lo que significa que muchos scripts seguían siendo servidos durante la interrupción cuando de otro modo habrían sido inaccesibles.
Línea base habitual: este porcentaje es cercano a lo normal para nosotros. Por ejemplo, el 17 de noviembre la tasa media de aciertos de caché fue del 74 %, lo que indica que seguíamos sirviendo nuestra cantidad habitual de scripts en caché.
El número total de solicitudes sí disminuyó, no obstante.**
cside está diseñado para gestionar interrupciones generalizadas
Este tipo de interrupciones generalizadas son inevitables debido a la naturaleza centralizada de los proveedores de nube, pero hacemos todo lo posible para limitar su impacto mediante despliegues multi-región de nuestro proxy y una arquitectura de "Fail Open" que garantiza que las solicitudes sigan procesándose incluso si todo falla.
También es importante señalar que nuestros servicios de edge están diseñados para operar en modo "aislado" si nuestro pipeline centralizado cae. Esto significa que, aunque no podamos comunicarnos con ese sistema, nuestro proxy seguirá operativo y podrá recibir y responder solicitudes de scripts. Por diseño, la caída de un sistema centralizado no puede dejar fuera de servicio a todos nuestros nodos de edge.
Puedes leer un desglose de cómo nuestra arquitectura evita que los sitios caigan aquí.
La entrada del blog de Cloudflare aquí también entra en gran detalle, y vale la pena leerla.
Nota adicional sobre el manejo de errores:
- La causa de la interrupción de Cloudflare resultó estar relacionada con un modo de fallo particular de los programas en Rust que utilizan llamadas a la función
.unwrap(), que fue lo que provocó los errores 500 que observamos. Nosotros no utilizamos esta función en absoluto en nuestro código de proxy, que también está escrito en Rust.
cside es un equipo de ingenieros web distribuidos con amplia experiencia. Entre ellos hay contribuidores principales a navegadores como Servo, ex-ingenieros de Cloudflare y contribuidores tempranos al código abierto de Tailwind y Bootstrap. Nos importa la web; tratamos nuestra infraestructura y arquitectura como una obra de arte. Aplaudimos a empresas como Cloudflare por compartir detalles profundos sobre sus incidentes, y hemos aprendido de ellos a lo largo de nuestras carreras para evitar que ocurran en la medida de lo posible.










