

TL;DR:
- Scripts no lado do cliente usados para verificações de segurança podem ser tornados ineficazes usando funcionalidades padrão do navegador, como sobrescritas de XHR.
- Embora isso possa ser prevenido, não conseguimos localizar nenhum fornecedor que tenha implementado um método de prevenção, tornando as soluções de segurança vulneráveis a bypasses.
- Soluções sem crawler/scanner/agente sofrem por design de visibilidade limitada. Isso permite que um agente malicioso detecte as varreduras e sirva código benigno ao scanner de segurança, enquanto serve código malicioso aos usuários finais.
- O objetivo deste post é ajudar a educar sobre o risco de ataques no lado do cliente e os exploits que agentes maliciosos usam para tornar soluções de segurança ineficazes. Também oferecemos soluções para prevenir esses métodos de bypass.
Neste Blog:
- Por que você deve testar suas ferramentas de conformidade
- Como contornar agentes JavaScript
- Como contornar CSP
- Como contornar crawlers
- Dicas de defesa e alternativas mais seguras
- Avisos legais e divulgação responsável

Objetivo e escopo. Este artigo é publicado exclusivamente para fins educacionais e defensivos. Os exemplos têm como objetivo explicar o comportamento geral do navegador e as limitações de design que podem afetar ferramentas de segurança no lado do cliente; eles não são um manual passo a passo de ataque e não são direcionados a nenhum fornecedor, produto ou organização específica. Não apoiamos o uso ilícito de nenhuma das técnicas discutidas aqui. Se você descobrir uma vulnerabilidade relacionada ao conteúdo deste post, siga a divulgação responsável — veja a seção "Divulgação responsável" ao final deste post. Todos os testes foram realizados em conformidade com os termos de serviço aplicáveis dos fornecedores e com as leis vigentes.

"Em um mundo onde ferramentas de conformidade podem falhar em técnicas básicas de contorno, ninguém está mais seguro e falsas sensações de segurança ampliam os problemas em questão."
- Simon Wijckmans, CEO, cside

Por que você deve testar suas ferramentas de conformidade/segurança no lado do cliente
Ficamos em dúvida se deveríamos escrever este artigo. Por um lado, não queremos expor fornecedores. Por outro, quando soluções de segurança são vendidas mas podem ser facilmente contornadas, todos estamos em risco. Criamos a cside para construir uma internet mais segura, com o objetivo de reduzir a ansiedade com segurança online.
Às vezes isso significa apontar vulnerabilidades em perímetros de segurança, especialmente quando elas decorrem de limitações conhecidas da plataforma.
Embora respeitemos que, para muitas empresas, a conformidade exige uma ferramenta que apenas marque uma caixa, enxergamos a conformidade como uma oportunidade de melhorar a segurança de uma plataforma. Especialmente quando esses requisitos de conformidade foram criados com o propósito de prevenir a execução de ataques.
Imagine um detector de fumaça de última geração que detecta um incêndio com perfeição, mas tem seu fio de alarme cortado antes de soar o aviso. A detecção é perfeita, mas a resposta nunca acontece. Essa é a realidade perigosa de algumas soluções de segurança no lado do cliente que operam dentro de um navegador web.
Quando um navegador carrega uma página, os scripts são executados no mesmo ambiente JavaScript e podem interagir com objetos globais compartilhados. Em certas condições, isso pode permitir que um script observe ou modifique outro. Mesmo detecções sofisticadas no lado do cliente podem ser limitadas se seus relatórios de saída forem interrompidos. Esse é um risco prático que os defensores devem considerar ao depender exclusivamente de telemetria no lado do cliente. Um script malicioso pode interferir nos relatórios de saída de uma ferramenta de segurança, o que em alguns casos pode reduzir significativamente a visibilidade sobre um incidente em andamento.
Por esse motivo, a cside decidiu não depender totalmente de detecções baseadas no lado do cliente, optando por uma abordagem mais avançada e criteriosa.
Como contornar um Agente JavaScript
A principal forma de um navegador se comunicar com um servidor é por meio de requisições de rede, tipicamente usando a API fetch ou XMLHttpRequest (XHR). Para um desenvolvedor, essas podem parecer partes fundamentais e imutáveis do navegador. Na realidade, são simplesmente propriedades do objeto global window que qualquer script pode redefinir.
Muitos scripts legítimos interagem com a API fetch — essa é uma abordagem comum e amplamente conhecida.
No entanto, um script pode usar essas APIs para interagir com as chamadas de saída de fornecedores de segurança no lado do cliente. Isso é feito facilmente:
- Redefinindo window.fetch para inspecionar ou bloquear relatórios de segurança de saída.
- Modificando XMLHttpRequest.prototype.send para interceptar e descartar alertas.
- Encapsulando essas funções para alterar payloads de requisições, remover cabeçalhos de segurança ou registrar dados sensíveis.
Veja como isso é simples. Imagine que seu site carrega dois scripts:
- Um plugin de chat de terceiros que foi comprometido.
- Uma ferramenta de segurança.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>My Application</title>
<script src="https://false-sense-of-security.com/security.js"></script>
<script src="https://compromised-chat-plugin.com/plugin.js"></script>
</head>
<body>
</body>
</html>
Agora, veja o código que o plugin.js comprometido pode conter. Como muitos scripts fazem para fins legítimos, ele interage com a API do navegador XMLHttpRequest. Abaixo está um comportamento geral de software.
// NÃO EXECUTÁVEL: fluxo conceitual do atacante (apenas ilustrativo)// Este bloco evita intencionalmente JS executável. Ele explica em alto nível // os passos que um atacante poderia seguir para interferir na telemetria no lado do cliente. // NÃO cole isso em um runtime JS esperando que funcione — é puramente descritivo.
/ Passos conceituais que um atacante poderia usar (alto nível): 1) DETECT_TELEMETRY_SENDER(stack): usar heurísticas / marcadores de runtime para adivinhar qual script está tentando enviar telemetria. 2) INTERCEPT_OUTBOUND_CALL(request): interromper, modificar ou descartar a requisição. 3) LOG_DECISION(info): opcionalmente registrar que uma chamada de telemetria foi suprimida. /
/* ---------- Operações conceituais (NÃO são funções reais) ---------- */
DETECT_TELEMETRY_SENDER(stack) // retorna: SENDER_MATCHED | NO_MATCH // NOTA: "stack" é uma representação conceitual do contexto de runtime
INTERCEPT_OUTBOUND_CALL(request) // resultados possíveis (conceitual): DROP | MODIFY(request) | FORWARD(request)
LOG_DECISION(info) // registrar decisão para análise (conceitual)
/* ---------- Cenário simulado (somente texto) ---------- */
// Runtime simulado: o atacante inspeciona a call stack atual (conceitualmente) SIMULATED_STACK = "...security.js at ..."
// Etapa de detecção conceitual DETECT_RESULT => DETECT_TELEMETRY_SENDER(SIMULATED_STACK) // => SENDER_MATCHED
// Decisão de interceptação conceitual INTERCEPT_OUTCOME => INTERCEPT_OUTBOUND_CALL({ to: "/telemetry" }) // => DROP
// Log simulado LOG_DECISION("Telemetry report suppressed (conceptual)")
/* ---------- Saída simulada do console (para compreensão do leitor) ---------- */ // >> DETECT_TELEMETRY_SENDER(...) => SENDER_MATCHED // >> INTERCEPT_OUTBOUND_CALL(...) => DROP // >> LOG: "Telemetry report suppressed (conceptual)"
Com esse comportamento de código em execução, sua ferramenta de segurança fica efetivamente impedida. Ela ainda pode detectar comportamento malicioso, mas seus pedidos de socorro (requisições fetch ou XHR) são interceptados e descartados no vazio. Você nunca saberá que um ataque ocorreu.
Como isso pode ser prevenido
Prevenir esse problema para requisições fetch é muito simples: basta copiar uma versão local dela, sem precisar nem renomear nada.
// Armazena `fetch` localmente para reutilizar depois:
const { fetch } = window;
// Usa a versão local de fetch mais adiante no código:
fetch(...)
XHR exige um pouco mais de trabalho, mas ainda assim é possível com algumas linhas de código:
// Armazena protótipos localmente para reutilizar depois:
const { apply } = Reflect;
const { open, send } = XMLHttpRequest.prototype;
const { XMLHttpRequest } = window;
// Em uma parte assíncrona do código:
const request = new XMLHttpRequest();
apply(open, request, ["POST", "/endpoint"]);
apply(send, request, []);
Nossa análise das metodologias de detecção comuns sugere que essas soluções podem ser suscetíveis aos conceitos de bypass documentados acima.
Recomendamos fortemente que qualquer fornecedor de segurança investigue essas abordagens para ajudar a proteger seus clientes.
Qualquer script de segurança deve ser executado primeiro. Caso contrário, um agente malicioso pode sequestrar as APIs que o script de segurança tenta proteger. Esse é um requisito fundamental.
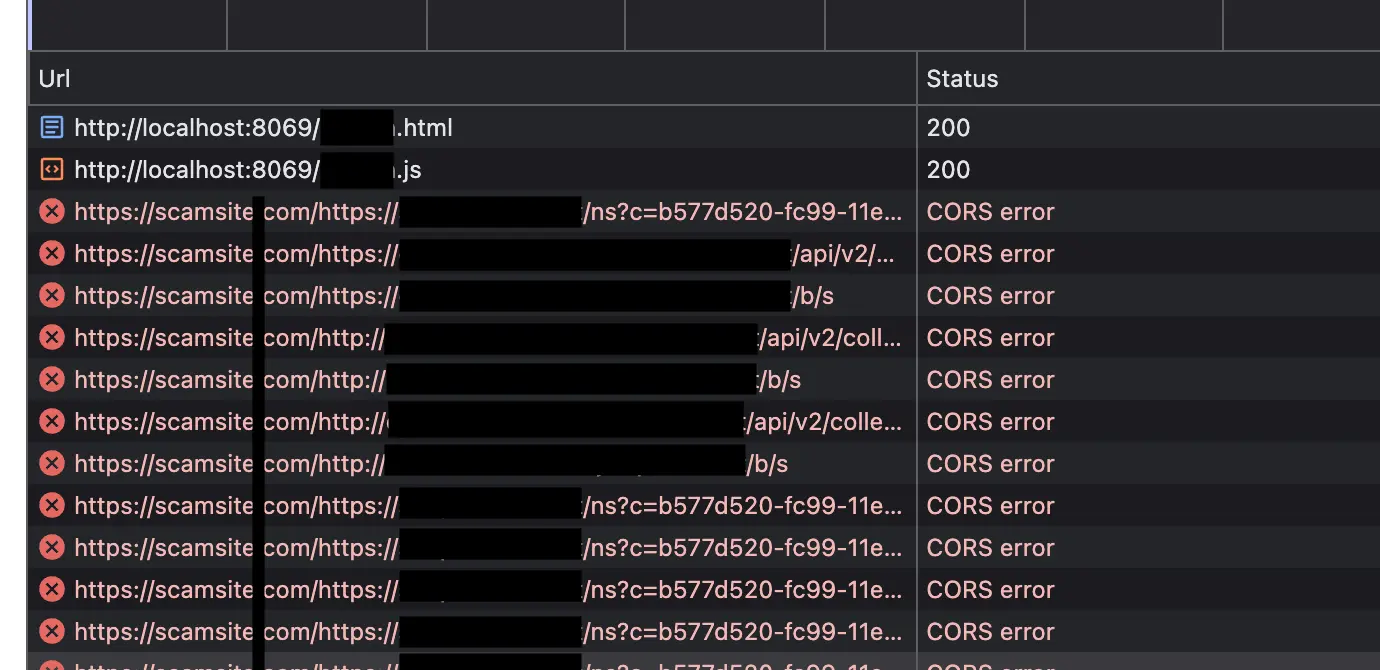
Como contornar uma solução 'sem agente'
Muitos fornecedores oferecem uma abordagem 'sem agente'. Trata-se efetivamente de um scanner ou crawler hospedado em uma plataforma de nuvem. Como qualquer aplicação, as requisições de rede precisam vir de algum lugar. E para a maioria dessas soluções, elas se originam de um endereço IP pertencente a provedores de nuvem.
Quando uma requisição de rede é feita, um cabeçalho de requisição é enviado junto, incluindo vários dados valiosos.
Host, User-Agent, Accept-Language, Referer (grafado intencionalmente de forma incorreta) e muitos outros.
A infraestrutura de um script buscado no lado do cliente vê esses valores e decide qual versão do script servir. Isso é lógico e existe por boas razões. Uma ferramenta de marketing pode servir versões diferentes de seu script com base no navegador da requisição ou na localização do usuário, para simplificar a conformidade com privacidade. Da mesma forma, anúncios, por exemplo, são aleatórios, mudam o tempo todo e são JavaScripts no lado do cliente. Scripts no lado do cliente são recursos dinâmicos e muitas soluções precisam dessa capacidade dinâmica.
No entanto, isso é uma oportunidade para um agente malicioso. Para ilustrar:
// Pseudo-lógica ilustrativa; não destinada a produção ou uso indevido.const CLOUD_ASNS = new Set([ // ASNs comuns de provedores de nuvem. Adicione mais se necessário 16509, // AMAZON-02 14618, // AMAZON-AES 24940, // HETZNER 212317, // HETZNER 398657, // MICROSOFT AZURE DEDICATED ]);
export default { async fetch(request) { // o servidor adiciona informações de rede na requisição const asn = request.xyz?.asn;
<span class="kw">const</span> body = CLOUD_ASNS ? <span class="str">`console.log("we're good");\n`</span> : <span class="str">`console.log("we're bad");\n`</span>; <span class="kw">return new</span> Response(body, { headers: { <span class="str">"content-type"</span>: <span class="str">"application/javascript; charset=utf-8"</span>, <span class="str">"cache-control"</span>: <span class="str">"no-store"</span>, }, });
}, };
O exemplo acima pode estar em qualquer tipo de servidor web, incluindo plataformas PaaS simples que não exigem nenhum nível de verificação.
O que o script acima faz é bastante simples. Quando uma requisição vem de um provedor de nuvem, serve um script limpo. Qualquer outra requisição recebe um script malicioso.
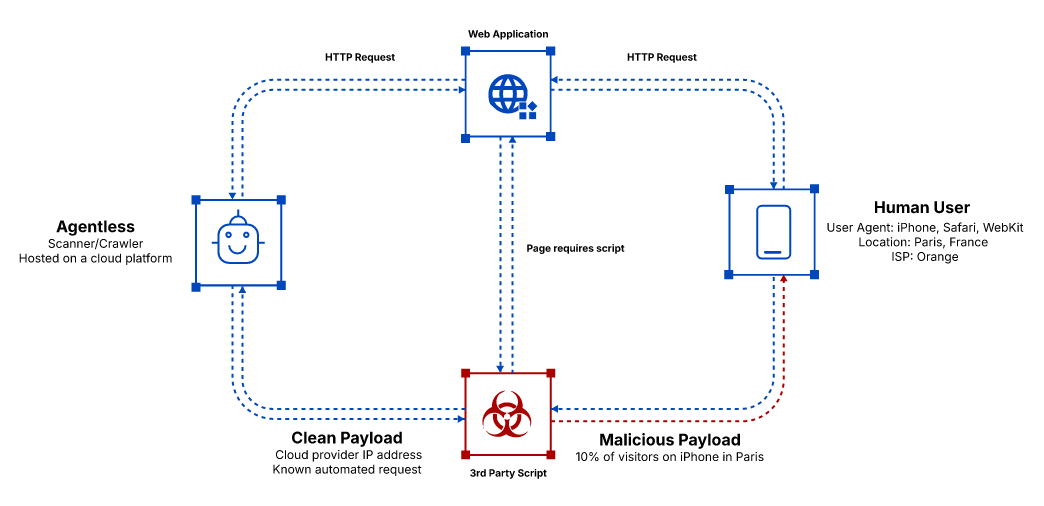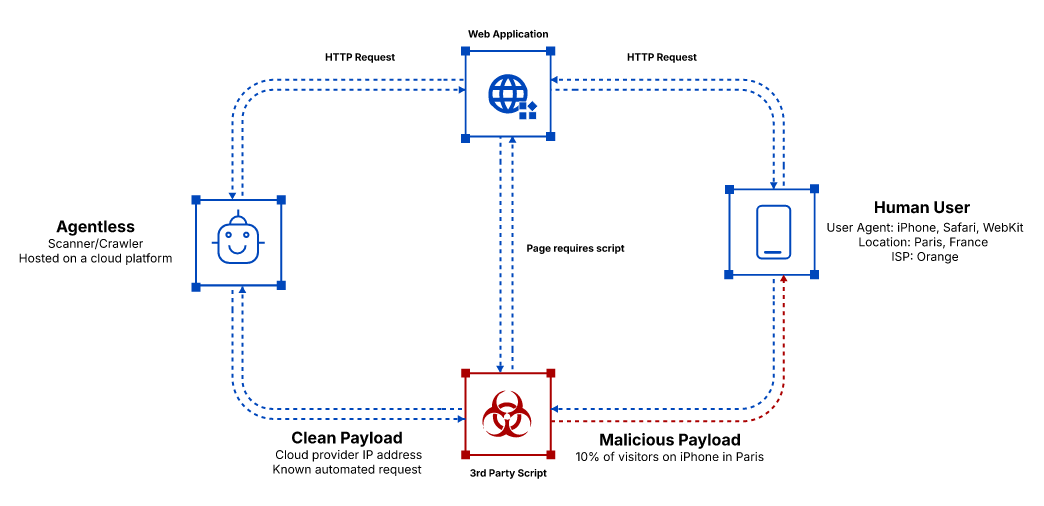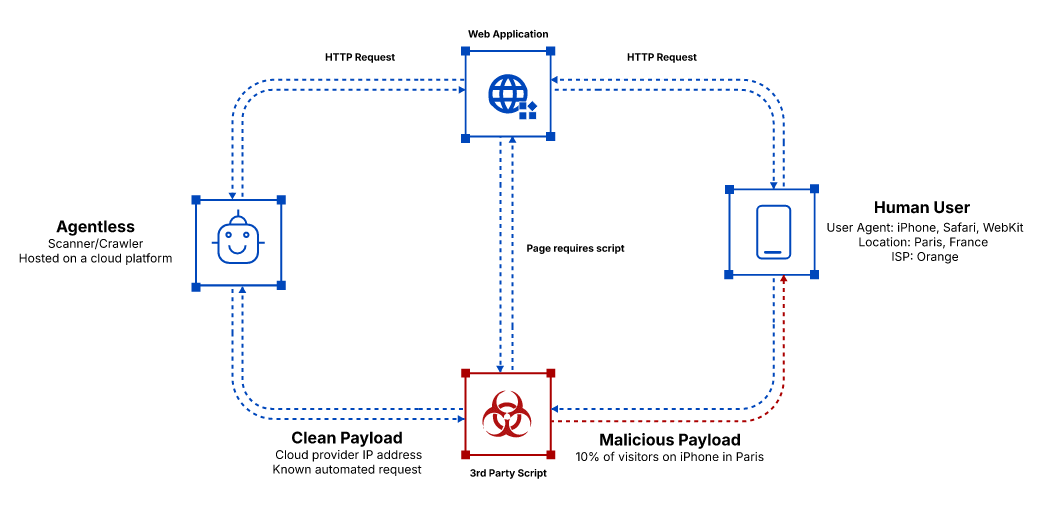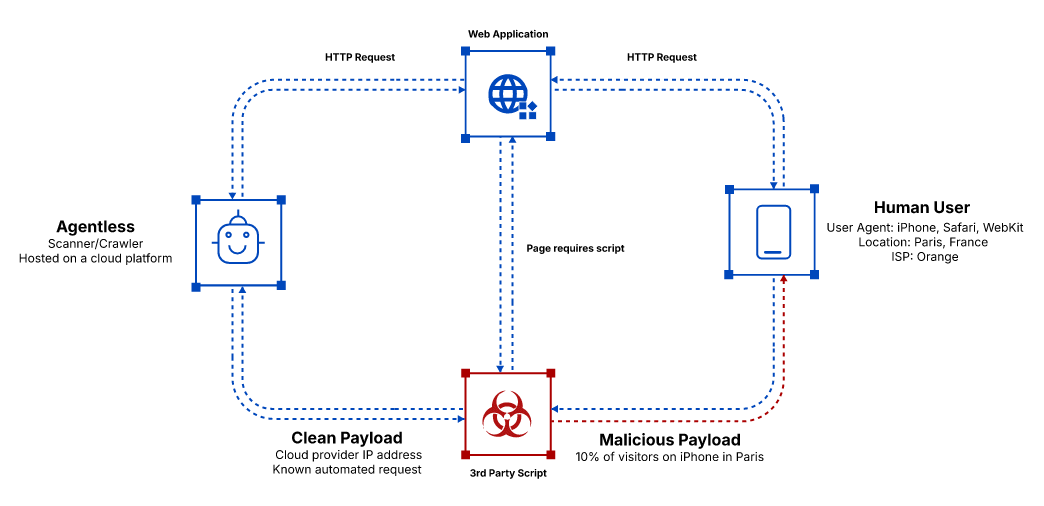
É claro que o agente malicioso poderia adicionar mais lógica. Por exemplo, servir o script malicioso apenas quando as ferramentas de desenvolvedor estiverem fechadas e somente em 5% das vezes, tornando mais difícil a detecção por revisão manual.
Isso pode reduzir substancialmente a visibilidade que uma solução baseada em crawler tem para ataques direcionados.
Usar um proxy residencial para parecer um usuário residencial normal provavelmente não fará diferença significativa. Um agente malicioso ainda consegue detectar o uso de um proxy residencial.
O espaço de endereços IPv4 conta com 4,3 bilhões de endereços IP, o IPv6 tem 340 undecilhões (sim, essa palavra existe), os user-agents de navegadores mudam o tempo todo... há níveis infinitos de entropia e um agente malicioso sempre pode amostrar um ataque. No fim das contas, nenhum método artificial para fazer algo parecer humano é de fato humano. Agentes maliciosos dedicados encontrarão formas de diferenciar um usuário humano real de um fluxo automatizado. As páginas de marketing dos fornecedores podem levar você a acreditar no contrário, mas fatos técnicos são fatos técnicos.
Outro método simples é fazer uma sub-requisição no lado do cliente com base em parâmetros disponíveis no navegador. Isso permite usar toda a extensão das APIs do navegador para decidir se deve ou não fazer uma sub-requisição.
Muitas soluções baseadas em crawler simplesmente verificam a URL de origem em uma lista de nomes de domínio maliciosos conhecidos, obtidos de provedores de feeds de ameaças. O problema com essa abordagem é que um ataque direcionado não será sinalizado e pode levar muito tempo para que um ataque seja percebido. Agentes maliciosos também podem facilmente evitar a detecção de domínios maliciosos usando nomes de domínio amplamente utilizados, como googletagmanager.com, para hospedar os scripts maliciosos.
Uma solução baseada em crawler aborda uma ameaça de segurança dinâmica com uma mentalidade de segurança estática. Embora conveniente, isso não funciona por design. Para ilustrar ainda mais esse ponto, vamos analisar alguns métodos de ataque comuns e como eles contornam a detecção.
Ataques com Geofencing
O que são: Ataques com geofencing servem um script malicioso apenas para usuários em localizações ou faixas de IP específicas (por exemplo, certas faixas de operadoras móveis no Reino Unido ou na UE) e servem um script benigno para todos os demais.
Por que scanners os perdem:
- Scanners, crawlers e ferramentas "sem agente" quase sempre rodam a partir de IPs de provedores de nuvem ou faixas de proxy conhecidas.
- Atacantes podem facilmente manter uma lista de ASNs de nuvem e evitar enviar payloads maliciosos para esses IPs.
- Como resultado, o scanner vê repetidamente o script "limpo" e nunca observa o ataque real.
Por que a cside os detecta:
- A cside observa scripts conforme eles são executados nos navegadores de usuários reais, em redes residenciais e móveis reais.
- Se um script se comportar de forma maliciosa para qualquer usuário real, a cside pode detectar o comportamento e, no modo gatekeeper, até mesmo bloquear o payload antes que ele seja executado.
Em outras palavras, o Reflectiz vê o que os atacantes permitem que seus scanners vejam; a cside vê o que os atacantes realmente enviam para seus usuários.
Ataques Direcionados por User-Agent
São ataques onde um payload malicioso é injetado apenas em determinados navegadores, por exemplo selenium, Safari, Chromium ou um sistema operacional específico.
A maioria dos scanners, crawlers e, neste caso, soluções 'sem agente' se origina de um conjunto previsível de strings User-Agent. Raramente emulam cabeçalhos de dispositivos móveis.
E nos raros casos em que um scanner altera seus User-Agents, o agente geralmente não está alinhado com os payloads reais das requisições. Scanners geralmente rodam em sistemas operacionais baseados em Linux, o que significa que um agente malicioso perceberá pelo pacote TCP da requisição qual sistema operacional está sendo realmente usado. Isso resulta no payload malicioso não ser enviado ao scanner, já que Linux raramente é usado por um usuário humano real.
Ataques com Janela de Tempo
São ataques que só são executados em horários específicos do dia. Por exemplo: fora do horário comercial, quando as equipes de segurança não estão presentes. Scanners rodam periodicamente, então uma abordagem com janela de tempo pode facilmente resultar no script benigno sendo escaneado, mas não o script malicioso.
Execução de Código Camuflada ou Condicional
São ataques que aproveitam ações do usuário para injetar um script malicioso. Toda a extensão das APIs do navegador pode ser usada aqui, por exemplo verificar movimentos do mouse, exigir um determinado ritmo na entrada do teclado, verificar a existência de cookies, análise de tempo (usada para detectar navegadores headless)...
Comumente, esse método é usado para servir o payload malicioso apenas uma vez, de modo que um pesquisador de segurança não consiga encontrá-lo novamente. Isso é particularmente desafiador, pois as ferramentas de desenvolvedor nos navegadores frequentemente não armazenam estados anteriores a antes de as ferramentas serem abertas, tornando necessário um recarregamento da página.
Um scanner nunca conseguirá emular o comportamento real de um usuário da mesma forma que um usuário real faria.
Payloads Dinâmicos por Sessão
São ataques onde o agente malicioso gera automaticamente payloads maliciosos únicos para cada usuário real, usando técnicas como encapsulamento de scripts com chaves dinâmicas, JavaScript polimórfico, lógica estilo A/B testing... Frequentemente usando os indicadores de autenticação do usuário como condição para injetar os payloads maliciosos.
Envenenamento Intermitente da Cadeia de Suprimentos
Esse é um método extremamente comum usado em ataques estilo Magecart. Um agente malicioso pode simplesmente amostrar o ataque para servir o conteúdo do script malicioso a apenas 1% dos usuários. Esse método torna muito mais difícil para um visitante notar o ataque, pois a injeção totalmente aleatória do script torna a reprodução do ataque muito mais complicada.
Conclusão
Com base em capacidades fundamentais do navegador publicamente documentadas e na funcionalidade padrão do JavaScript, abordagens baseadas em crawler podem enfrentar as limitações descritas acima.
Incentivamos os fornecedores a documentar claramente essas limitações e a não superestimar suas capacidades. Os clientes devem ter as informações necessárias para tomar decisões de implantação informadas, no melhor interesse da segurança da web.
Como contornar o CSP
Outra abordagem de segurança comumente usada são as políticas de segurança de conteúdo (Content Security Policies).
O CSP pode ser útil para limitar a exposição, reduzindo o escopo de fontes permitidas. Mas muitos sites usam ferramentas abertas para o mundo inteiro fazer upload de scripts. Se uma política não for restritiva o suficiente, isso levará a um bypass fácil. Mas mesmo que uma política seja suficientemente restritiva, um atacante pode optar por realizar o ataque de uma forma que o CSP não monitora.
Como isso funcionaria: uma vez que um agente malicioso encontra seu caminho para uma aplicação web, ele pode injetar uma sub-requisição para um container do Google Tag Manager. Exemplo:
<script async src="https://www.googletagmanager[.]com/gtm.js?id=GTM-XXXXXX"></script>Dentro desse container, ele pode incluir quaisquer scripts que desejar. Incluindo scripts inline, que são ainda mais difíceis de proteger.
Como o CSP não tem contexto real do payload do script, a visibilidade é bastante limitada.
Algumas soluções tentam contornar isso fazendo um fetch para o script após o fato.
Mas o mesmo problema do crawler se aplica: qualquer coisa que pareça não humana provavelmente receberá uma resposta diferente da que um usuário humano receberia.
Embora você pudesse especificar o container do tag manager no CSP, isso não é muito comum. Há também outros domínios como "githubusercontent[.]com" que enfrentam o mesmo problema.
E, em última análise, se uma fonte for comprometida, seja por um incidente no fornecedor ou pelo vencimento do nome de domínio, o CSP não conseguirá ajudar.
Ao contrário do método de script no lado do cliente, não conseguimos encontrar uma técnica confiável dentro do CSP que evitasse o uso de um domínio confiável como método de bypass. Os próprios proprietários dos domínios poderiam tomar medidas preventivas, mas não o fizeram até hoje. O CSP tem limitações, mas como em qualquer programa de segurança, a estratégia de camadas é uma boa prática. O CSP está sendo usado para mais do que foi inicialmente projetado.
Empresas que adotam o CSP frequentemente têm dificuldades para mantê-lo e lidam com interrupções regulares de ferramentas no lado do cliente quando as políticas bloqueiam mudanças.
A cside está ativamente envolvida em organizações de padrões web para tentar melhorar a especificação do CSP e outros métodos como o SRI.
Alternativas mais seguras (a abordagem da cside)
A equipe da cside tem experiência substancial em segurança no lado do cliente. Ao longo de nossas experiências, identificamos que agentes maliciosos operam em um nível de sofisticação que supera algumas abordagens de segurança. Se a recompensa for alta, qualquer lacuna em um modelo de detecção de segurança é uma oportunidade para um agente malicioso.
Dadas as limitações da especificação dos navegadores para segurança no lado do cliente, precisamos ser criativos, razão pela qual abordamos a segurança no lado do cliente de forma diferente de qualquer outra solução no mercado.
- Modo Direto - Mais Fácil: Verificamos os comportamentos dos scripts no navegador e buscamos os scripts do nosso lado. Em seguida, verificamos se recebemos o mesmo script. Não nos colocamos no caminho de um script a menos que você nos peça explicitamente. Basta adicionar um script ao site, leva segundos.
- Modo Gatekeeper - Mais Seguro: Verificamos os comportamentos dos scripts e a cside se posiciona no meio entre o terceiro não controlado e o usuário final — apenas scripts que você ainda não confia. Basta adicionar um script ao site, leva segundos.
- Modo de Varredura - Mais Rápido: Se você não puder adicionar um script ao site, a cside fará a varredura. Usaremos a inteligência de ameaças da cside coletada por milhares de outros sites com bilhões de visitantes combinados para ajudar a proteger seu site da melhor forma possível.
A combinação das abordagens acima nos aproxima da cobertura total tecnicamente possível hoje.
Como benefício adicional, com algumas das abordagens que adotamos, conseguimos tornar os sites mais rápidos dependendo dos scripts na página. Colocar uma solução no meio só torna as coisas mais lentas se elas já estiverem totalmente otimizadas, o que frequentemente não é o caso.
Com isso, a cside ajuda empresas a alcançar conformidade, seja com foco em segurança ou privacidade.
A cside contribui ativamente para o W3C na esperança de criar atenção para a segurança no lado do cliente. Com o objetivo de fazer ajustes na especificação do navegador para permitir uma segurança no lado do cliente totalmente à prova de falhas.
Na cside, capturamos ataques. Se você está lendo este post, provavelmente é um alvo de valor suficientemente alto para que um agente malicioso invista algum nível de capacidade mental para inspecionar como sua segurança web funciona. É melhor estar seguro e assumir que um agente malicioso tentará contornar as soluções de segurança que você usa. Portanto, use soluções que pensam um passo à frente.
Aviso Legal e Porto Seguro
Este post é apenas para fins informativos e educacionais. Não constitui aconselhamento jurídico, e as opiniões e análises técnicas expressas são nossas. Nada aqui deve ser interpretado como admissão de responsabilidade por qualquer parte.
Nenhuma das abordagens ou amostras de código mencionadas acima é avançada ou usada exclusivamente para fins maliciosos. Esses são casos de uso básicos de JavaScript, de forma alguma são proprietários. Os trechos compartilhados são ativamente usados em scripts no lado do cliente para fins legítimos. Não somos responsáveis por qualquer uso dessas funções básicas de JavaScript por uma parte maliciosa.
Todo o código de exemplo e pseudocódigo são apenas ilustrativos. São intencionalmente genéricos, não proprietários e não projetados para rodar em ambientes reais. Seu propósito é destacar considerações defensivas, não fornecer exploits funcionais a atacantes.
Atenção: tentar aplicar essas técnicas em sistemas que você não possui, ou sem permissão explícita, pode violar leis como o Computer Fraud and Abuse Act dos EUA, o Computer Misuse Act do Reino Unido ou regras similares em outras jurisdições.
Apoiamos ativamente a pesquisa de segurança de boa-fé. Se você seguir o processo de Divulgação Responsável descrito abaixo, trataremos sua pesquisa como autorizada e não tomaremos medidas legais contra você. Em resumo, este conteúdo é fornecido para ajudar os defensores a fortalecer as proteções, não para permitir comportamento malicioso.
Divulgação Responsável
Se você acredita ter descoberto uma vulnerabilidade relacionada ao conteúdo deste post (incluindo scripts de terceiros ou integrações que referenciamos), por favor não publique detalhes do exploit publicamente. Em vez disso, envie um e-mail para
hello@cside.com com o assunto "Vulnerability report [short title]".
Inclua etapas reproduzíveis, URLs afetadas e um método de contato seguro. Confirmaremos o recebimento em até 5 dias úteis e coordenaremos a remediação. Não tomaremos medidas legais contra pesquisadores de boa-fé que seguirem estas diretrizes.










